RAG vs Graph Memory: Collaboration Impact
RAG vs Graph Memory: Collaboration Impact
Large Language Models (LLMs) lack memory, which makes it harder for engineering teams to integrate them into workflows. Two approaches address this issue: RAG (Retrieval-Augmented Generation) and graph memory. Here's what you need to know:
- RAG retrieves text chunks based on semantic similarity. It's great for simple lookups but struggles with complex, multi-step reasoning and relationship-based queries.
- Graph memory organizes data as connected nodes and relationships, enabling it to handle multi-hop reasoning, track dependencies, and maintain context over time.
Key Differences:
- RAG is faster and cheaper but often misses connections and struggles with evolving data.
- Graph memory excels at reasoning across dependencies but is slower and more expensive.
When to Use:
- Use RAG for straightforward Q&A and document retrieval.
- Use graph memory for complex workflows, dependency tracing, and long-term context.
Quick Comparison:
| Feature | RAG | Graph Memory |
|---|---|---|
| Mechanism | Semantic similarity search | Graph traversal |
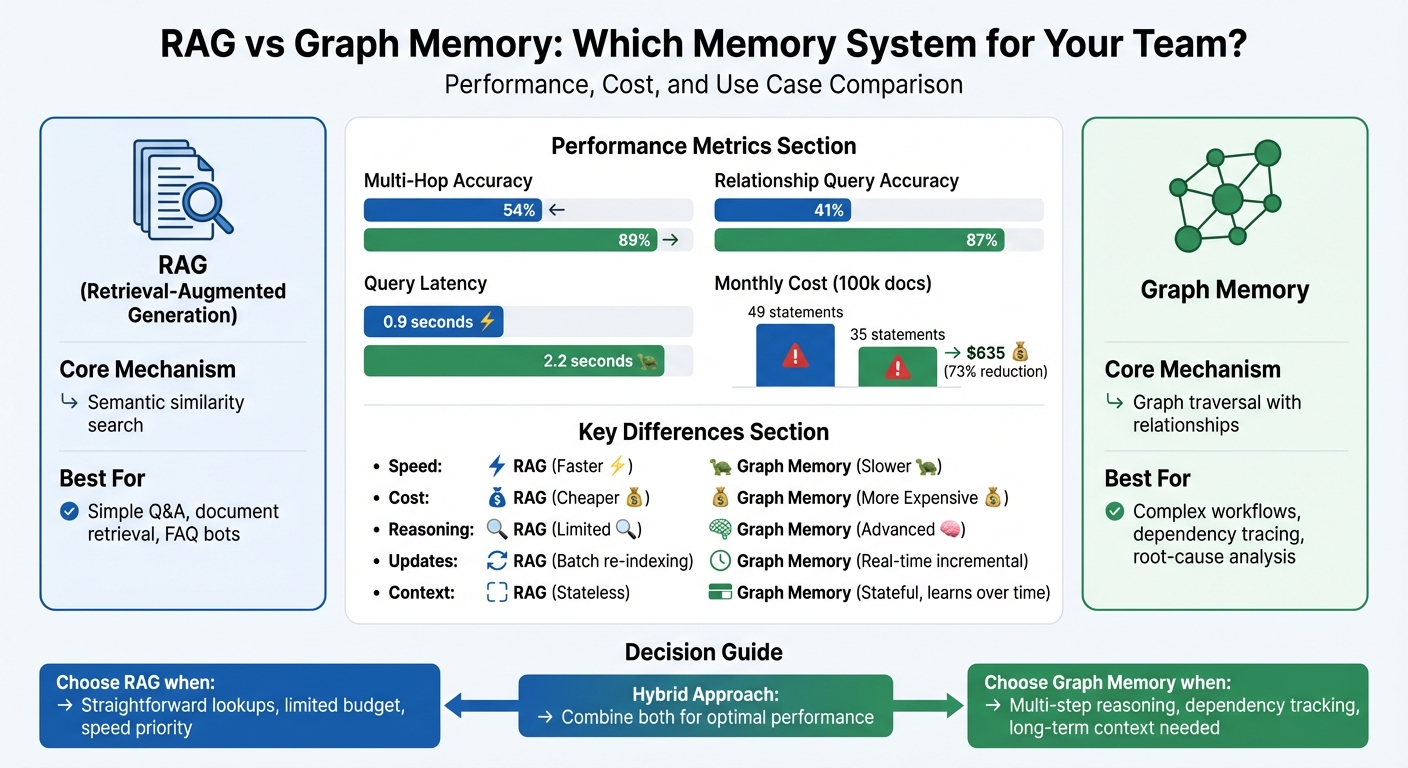
| Accuracy (Multi-Hop) | 54% | 89% |
| Cost (100k docs/month) | $320 | $635 |
| Query Latency | 0.9 seconds | 2.2 seconds |
Graph memory is better suited for engineering teams needing precise reasoning and collaboration support. Hybrid systems combining both approaches may offer the best of both worlds.
RAG vs Graph Memory: Performance Metrics and Use Cases Comparison
Traditional RAG vs. GraphRAG: A Comparative Overview!
sbb-itb-1218984
What is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) bridges Large Language Models (LLMs) with external data sources, enhancing their ability to provide informed responses by tapping into searchable document libraries. It works through a process of breaking down documents into smaller chunks, creating embeddings that capture their semantic meaning, and storing these in a vector database. When a query is made, it’s embedded in the same way and used to perform a nearest-neighbor search, retrieving relevant chunks to guide the LLM’s response.
RAG’s power lies in its ability to recognize semantic similarities. For instance, it understands that phrases like "revenue increase" and "growth in earnings" are conceptually linked. This makes it especially effective for handling unstructured, text-heavy datasets, such as those used in FAQ bots, document-based Q&A systems, or enterprise search tools.
"RAG is about semantic similarity, finding what sounds relevant. But it often stops there." – Sabika Tasneem, AI Product Builder, Memgraph
However, RAG has its limitations. It treats data as a collection of isolated text chunks, connected only by semantic proximity. A study from Google DeepMind, published in August 2025, highlighted a critical drawback: embedding-based retrieval systems often lack nuance. For example, "top-k cutoffs" used in retrieval can inadvertently exclude important details necessary for solving complex queries. While RAG performs well for straightforward retrieval tasks, it faces challenges when deeper, multi-step reasoning is required.
Where RAG Falls Short in Collaborative Settings
RAG’s efficiency in retrieving semantically related text comes with trade-offs, particularly in collaborative environments. Its systems are typically read-only and do not adapt automatically as information evolves. This static nature becomes an issue in settings where data changes frequently.
The biggest hurdle for RAG lies in its inability to handle multi-hop reasoning - queries that require connecting several pieces of information across different tools. Take this example: "Who approved the PR that fixed the bug reported by the customer?" Answering this requires navigating from a customer report in Zendesk to a Jira ticket, then to a GitHub pull request, and finally to the reviewer. RAG struggles here because it focuses on retrieving individual chunks of text that are semantically similar, without understanding how they relate to one another.
"The retrieval step finds documents that are semantically similar to your query, but semantic similarity isn't the same as relevance." – Kumar Kislay, CEO/Founder, Syncally
In multi-agent systems, these shortcomings can lead to issues like context pollution. For instance, specialized agents may retrieve chunks that are semantically close but irrelevant, wasting tokens and creating confusion in workflows. Research shows that systems relying solely on RAG produced 49 hallucinated statements compared to 35 when paired with a knowledge graph - a 73% reduction. Additionally, RAG-only systems missed relevant information in 54 instances when handling complex queries. These challenges highlight the need for more advanced approaches, such as graph memory, to address RAG’s limitations while staying aligned with the broader discussion.
What is Graph Memory?
Graph memory organizes information as a network of interconnected nodes, each linked by defined relationships. For instance, a node for "Service A" could be connected to "Service B" via an edge labeled "depends on", creating a clear, traceable path of causation.
This structure supports multi-hop reasoning, allowing the system to answer complex queries like, "Who approved the PR that fixed the bug reported by the customer?" The system traces the query step by step - from the customer report to the Jira ticket, then to the GitHub pull request, and finally to the reviewer - using explicit relationships rather than relying on vague semantic connections.
"RAG answers questions with the right data. GraphRAG answers them with the right context." – Sabika Tasneem, AI Product Builder, Memgraph
Graph memory evolves in real time, updating as new code changes, documents, or interactions are added. Some systems treat each piece of information as an independent fact, complete with metadata like timestamps, validity periods, and sources. This approach helps track changes over time and answer questions like, "What changed and when?".
To locate relevant information, graph memory uses vector search to find entry points, then follows explicit relationships for deeper insights. For example, in healthcare, this method improved diagnostic accuracy by 30% and cut data retrieval times by 40%. Overall, graph-enhanced queries have achieved around 90% accuracy, far outperforming the 60% accuracy typical of traditional RAG systems. This interconnected framework also strengthens team collaboration.
How Graph Memory Improves Team Collaboration
Graph memory acts as a shared context layer for AI agents, aligning them around interconnected data that tracks ownership, dependencies, and decision-making history. Real-world examples, like the Harness Software Delivery Knowledge Graph, show how this approach can drastically improve team workflows. For instance, in December 2025, Harness achieved results like 85% faster pipeline onboarding, seven times quicker issue resolution, and a 50% reduction in debugging time for engineering teams.
"The fundamental distinction lies in structure: A knowledge graph encodes explicit, machine-interpretable relationships." – Sunil Gattupalle, Harness
Graph memory also supports cross-departmental coordination. In January 2026, Ema used Context Graphs to unify Sales and Support operations. On January 14, 2026, a Support agent dealing with a high-value prospect’s delivery delay discovered via the graph that a Sales agent had approved a 15% discount two days earlier to close the deal by quarter-end. Armed with this insight, the Support agent upgraded the customer to Platinum tier and authorized overnight shipping, ensuring a fast and effective response.
For production engineers, graph memory captures critical institutional knowledge, such as why a particular workaround exists in a shell script, which team is responsible for a legacy service, or how various components interact across the stack. This is especially helpful during incidents when engineers need quick insights or during onboarding to understand complex dependencies.
The CORE memory system has showcased these benefits at scale, achieving 88.24% accuracy on the LoCoMo benchmark, which evaluates long-context memory retrieval across hundreds of conversation turns. Additionally, temporal knowledge graphs have demonstrated up to 18.5% better accuracy and 90% lower response latency for complex temporal reasoning tasks. These advancements lead to faster incident resolution, improved cross-team collaboration, and reduced cognitive strain on engineers.
RAG vs Graph Memory: Side-by-Side Comparison
Expanding on the earlier discussion of their strengths and weaknesses, here's a direct comparison of how RAG and graph memory systems influence collaboration, particularly for engineering teams. The two systems differ fundamentally in how they organize and retrieve knowledge. RAG processes information as separate text chunks, focusing on semantic similarity to answer queries. On the other hand, graph memory structures data as interconnected nodes and edges, allowing it to map relationships such as "Component → Subsystem → Failure" with precision.
The performance gap between the two systems is striking. A 2025 benchmark by Cognilium AI tested 500,000 enterprise documents, revealing that GraphRAG achieved 89% accuracy on multi-hop reasoning queries, compared to just 54% for traditional RAG. For relationship-based queries, such as tracing contract approvals or identifying service dependencies, GraphRAG reached 87% accuracy, while RAG lagged behind at 41%. These differences are particularly critical for tasks like dependency tracing, ownership assignment, and root-cause analysis - key components of effective engineering collaboration.
However, these systems also have practical trade-offs. RAG queries are faster, averaging 0.9 seconds, and cost approximately $320/month for 100,000 documents. Graph memory, while more accurate, takes 2.2 seconds per query and costs about $635/month, due to the additional requirements of a graph database. Another challenge for RAG is its tendency to hallucinate, generating 49 fabricated statements during testing, compared to 35 for graph memory - a 73% reduction. Graph memory also handles missing data more reliably, returning precise counts or "no results found", while RAG’s vector search often produces irrelevant results.
Comparison Table: RAG vs Graph Memory
| Feature | Traditional RAG | Graph Memory |
|---|---|---|
| Core Mechanism | Vector similarity search | Graph traversal with explicit relationships |
| Multi-Agent Support | Prone to per-agent context divergence | Shared, consistent global state |
| Dependency Reasoning | Limited; fails on multi-hop queries | Excels at tracing relationship paths |
| Update Mechanism | Batch re-indexing; requires re-embedding | Incremental; real-time node/edge updates |
| Context Persistence | Stateless; each query starts fresh | Stateful; learns from interactions over time |
| Query Latency | 0.9 seconds | 2.2 seconds |
| Infrastructure Cost | ~$320/month (100k docs) | ~$635/month (100k docs) |
| Multi-Hop Accuracy | 54% | 89% |
| Relationship Accuracy | 41% | 87% |
| Engineering Workflow Fit | Best for simple Q&A and documentation lookup | Best for root-cause analysis and compliance tracking |
| Failure Mode | Quietly hallucinates or misses connections | Stale edges if updates lag; schema drift |
These differences highlight how each system serves distinct engineering needs, shaping workflows in unique ways.
Impact on Engineering Workflows
The decision to use RAG or graph memory can reshape how engineering teams operate daily. Graph memory provides a centralized view of interconnected systems, documentation, and decision-making history, essentially creating a "living map" of engineering knowledge. This isn't just about quicker information retrieval - it's about uncovering the connections that make decisions traceable and encourage collaboration. These benefits ripple through areas like incident management and maintaining knowledge continuity within engineering processes.
This becomes especially important during service failures or dependency disruptions. When something breaks, graph memory can instantly highlight the "dependency radius", ownership details, and relevant historical patterns. In contrast, RAG systems might retrieve isolated text snippets mentioning similar incidents but fail to show how failures cascade across interconnected systems.
"Knowledge graphs - and especially the semantic layer behind them - benefit the entire engineering ecosystem, not just AI." – Sunil Gattupalle, Harness
Graph memory also plays a key role in preserving institutional knowledge, even as teams evolve. When senior engineers leave, their expertise often goes with them. Graph memory captures and organizes this knowledge into structured, digital assets that remain accessible, regardless of personnel changes. It also tracks the timeline of decisions, helping teams distinguish between current practices and outdated approaches. This prevents new team members from following obsolete advice that RAG systems might still surface as "relevant".
For teams leveraging AI, graph memory encourages direct "human-in-the-loop" interaction by allowing engineers to review and edit the graph structure themselves. This transparency builds trust in AI-generated insights, as the reasoning process becomes clear and verifiable. Tools like Knowledge Plane take this further by integrating graph and vector memory with Skills - automated jobs that keep the context up-to-date across code, documentation, tickets, and team communications. Unlike RAG systems, which require manual re-indexing, this setup ensures AI agents always work with fresh, relationship-aware data that mirrors the real dynamics of your engineering organization.
Conclusion: Selecting the Right Memory System
Deciding between RAG and graph memory directly impacts how AI can support engineering teams. RAG excels at straightforward lookups, retrieving isolated text chunks using semantic similarity. On the other hand, graph memory organizes data into a connected network, enabling reasoning across dependencies, tracking causality, and maintaining context.
For engineering teams dealing with intricate workflows, this distinction is critical. As Walid Shehata from DevRev explains: "RAG is excellent for lookup. Use graphs for reasoning". If your team needs to trace which commit caused a build failure, determine who approved an API deployment, or analyze cascading failures across interconnected systems, graph memory provides the precision and relational insight that RAG cannot match.
Graph memory achieves up to 95% accuracy in enterprise tasks, significantly outperforming RAG’s approximate 80%, especially in complex queries involving multiple entities. This makes it an essential tool for AI-powered teams tackling the challenges of engineering complexity.
To enhance performance and collaboration, hybrid systems now combine the strengths of both approaches. Platforms like Knowledge Plane integrate vector search for broad retrieval with graph memory’s structured reasoning. By synchronizing context across code, documentation, tickets, and chats, these systems ensure AI agents work with up-to-date, relationship-aware data - eliminating the need for constant manual re-indexing.
For teams aiming to maximize AI collaboration, start with RAG for basic lookups and transition to graph memory when reasoning across multiple entities and maintaining long-term context becomes crucial. This shift leads to faster incident resolution, better knowledge retention, and AI agents that truly understand the complexities of your engineering environment.
FAQs
What data should go into the graph?
In a graph memory system, it's important to map out entities and their relationships that are relevant to your specific domain or workflow. For instance:
- A product is linked to a supplier.
- A supplier serves a particular location.
- A warehouse holds specific product categories.
These relationships form a structured network that helps with reasoning and makes the system easier to interpret. Adding a semantic layer ensures that these connections are meaningful and consistent. This not only improves the accuracy of queries but also enhances contextual understanding within AI-driven workflows.
How do you keep graph memory up to date?
Graph memory remains current by consistently incorporating new data and relationships through methods like real-time ingestion, scheduled updates, or event-driven triggers. Tools such as Knowledge Plane’s Skills (scheduled jobs) work alongside graph and vector memory to ensure that context stays updated and relationships - like ownership and dependencies - are accurately maintained. Regular synchronization with external sources and automated updates help ensure the memory stays dependable for AI workflows.
When does a hybrid RAG + graph approach make sense?
When dealing with tasks that demand complex reasoning, understanding intricate relationships, or addressing multi-hop queries, a hybrid RAG (Retrieval-Augmented Generation) + graph approach shines. While standard RAG is great at pulling up similar documents, it often falls short in reasoning through deeper connections or relationships within the data. By incorporating a knowledge graph layer, this hybrid method introduces a structured way to understand entities and how they link together. This makes it especially useful in fields like engineering or enterprise environments, where accurate reasoning and working with interconnected data are crucial.