Memory Partitioning in Multi-Agent Systems
Memory Partitioning in Multi-Agent Systems
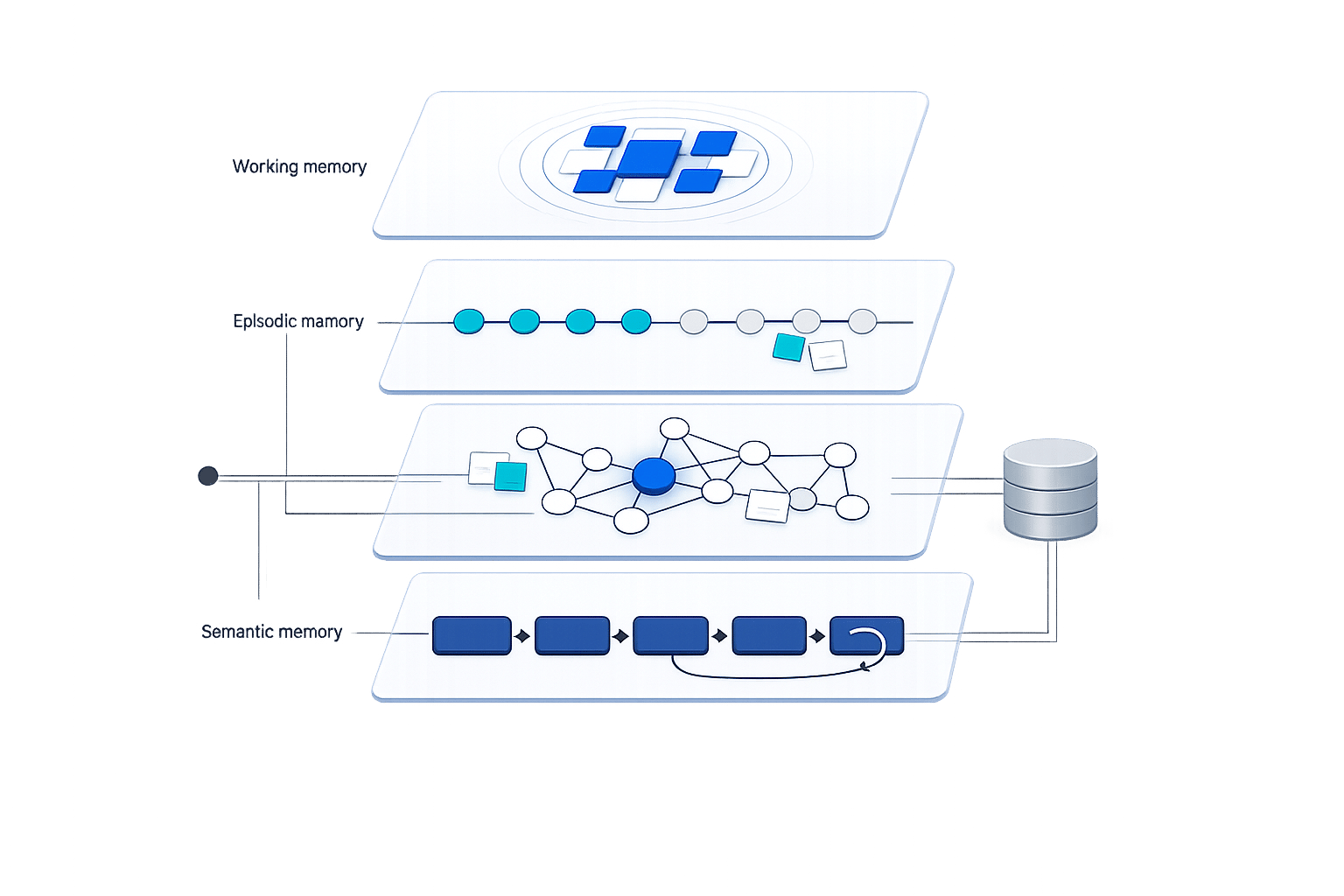
Memory partitioning is a method to organize an AI agent's memory into distinct layers, improving accuracy, reducing costs, and preventing errors in multi-agent systems. By dividing memory into Working, Episodic, Semantic, and Procedural types, agents can access and store information more efficiently. This approach also separates Private (agent-specific) and Shared (collaborative) memory to streamline communication and avoid duplication.
Key Takeaways:
- Memory Types:
- Working Memory: Short-term, immediate context.
- Episodic Memory: Past experiences, stored in vector databases.
- Semantic Memory: General knowledge in structured formats.
- Procedural Memory: Skills and workflows.
- Benefits:
- Improves retrieval accuracy and reduces token usage by up to 85%.
- Prevents context interference and misalignment (responsible for 36.9% of failures).
- Enables better coordination in multi-agent setups, improving performance by over 90%.
- Challenges:
- Managing context rot, silos, and privacy concerns.
- Coordination overhead due to frequent synchronization.
Real-World Example:
Anthropic's 2025 multi-agent system avoided redundant tasks and improved efficiency by 90.2% using shared memory. Techniques like structured memory templates and conflict partition scheduling further enhance reliability and scalability.
Tools to Consider:
- Systems like Knowledge Plane integrate memory management with hybrid graph and vector databases, offering traceable and efficient memory solutions for engineering teams.
Memory partitioning transforms how agents collaborate, ensuring faster decisions, reduced costs, and fewer errors in complex systems.
Memory Partitioning Types and Benefits in Multi-Agent AI Systems
Build Hour: Agent Memory Patterns
sbb-itb-1218984
How Memory Partitioning Works
Memory partitioning is built on three core ideas: using different types of memory, organizing memory hierarchically, and allocating memory based on specific roles.
Different Memory Types
Think of working memory like your computer's RAM - it holds immediate, short-term information that fits within the LLM's context window. Episodic memory, on the other hand, stores specific past experiences in vector databases indexed by session. Meanwhile, semantic memory acts as a long-term knowledge base, keeping persistent facts in structured formats like knowledge graphs or relational databases. Lastly, procedural memory encodes learned skills or workflows in formats such as PDDL or Pydantic schemas.
The problem with treating all memory the same is that it ignores the fact that different types of information have unique needs for persistence, access, and quality. This often leads to production failures.
As Suchitra Malimbada explains in the Agentic AI Engineering Guide, "Treating all memory identically is the root cause of most production failures. Information has different persistence requirements, access patterns, and quality thresholds."
To address this, systems like MemGPT use a paging mechanism to dynamically load and remove data, reducing token costs by 85%–95% compared to simpler, less efficient methods.
Hierarchical Memory Organization
By leveraging the distinctions between memory types, hierarchical organization structures data into layers of abstraction. This setup moves from broad categories to specific details, making retrieval faster and more efficient. Using index-based routing, irrelevant data is filtered out early, avoiding the need to scan an entire flat vector database.
For example, in August 2025, researchers from the University of Southampton and the Alan Turing Institute introduced the "Intrinsic Memory Agents" framework. This system was designed for a complex data pipeline task and included eight specialized agents, such as a Data Engineer Agent and an Infrastructure Engineer. Each agent used role-specific JSON memory templates. Although this approach increased token usage by 32%, the designs produced were far more scalable (scoring 7 versus 5) and reliable (scoring 4.89 versus 3.56) compared to standard methods.
Role-Based Memory Allocation
Role-based memory allocation ensures that agents access only the data relevant to their specific responsibilities. This approach helps prevent the misalignment issues that cause 36.9% of multi-agent system failures, where agents work with inconsistent views of shared state.
Modern systems employ tools like Role-aware Context Routing (RCR-Router) to select the most relevant memory subset for each agent's role. This keeps token usage efficient while maintaining context accuracy. Security measures also play a key role by restricting memory access to authorized agents. This prevents issues like context poisoning, where one agent's errors or hallucinations could corrupt the memory shared by the entire system. Advanced databases like Redis and Qdrant support these systems, offering p95 latencies of 15 ms for cached data and 150 ms for uncached data.
Memory Partitioning Techniques
To refine multi-agent memory management, certain memory partitioning techniques can significantly enhance efficiency. Among the most effective methods are compositional memory models, structured memory templates, and conflict partition scheduling. Each approach offers distinct advantages tailored to specific scenarios.
Compositional Memory Models
Compositional memory models organize memory into distinct functional layers, mirroring how human cognition operates. These layers include working, episodic, semantic, and procedural memory. This structure minimizes "context distraction", where vital details might be overshadowed by irrelevant data.
For example, in August 2025, Sizhe Yuen and colleagues applied the Intrinsic Memory Agents framework to design data pipelines. By utilizing eight specialized agents (e.g., Data Engineer, Infrastructure Engineer), their system achieved higher scores in scalability (7 vs. 5) and reliability (4.89 vs. 3.56) compared to traditional methods, albeit with a 32% increase in token usage per output.
To optimize performance, match memory storage to its specific access needs:
- Use in-memory caches for working memory requiring millisecond-level access.
- Store episodic memory in append-only logs for audit purposes, akin to a "flight recorder."
- Maintain semantic memory in vector or graph databases for long-term retrieval.
- Version procedural memory in code repositories, ensuring skills remain both auditable and transferable.
Structured Memory Templates
Structured memory templates employ predefined formats, often using JSON slots, to organize agent-specific memories. These templates ensure consistency across fields such as "proposed_solution", "domain_expertise", and "execution_trace". This method allows agents to update only their designated fields, avoiding cross-contamination of data. For instance, a data engineer focuses solely on fields related to data pipelines, while an infrastructure agent manages deployment-specific concerns.
"Agent performance is an end-to-end data movement problem. Even if the model is powerful, if relevant information is stuck in the wrong layer (or never loaded), reasoning accuracy and efficiency degrade." - Zhongming Yu and Jishen Zhao, University of California, San Diego
In January 2026, Shuchismita Sahu implemented a robust system using a database stack that included PostgreSQL, Redis, Qdrant, and Neo4j. By leveraging batch operations and connection pooling, the team reduced database load by 70% and improved decision quality by 3.5×, achieving 50,000 memory operations per second with 99.95% uptime over 90 days.
Conflict Partition Scheduling
Once memory is structured, managing concurrent updates becomes crucial. When multiple agents access shared memory simultaneously, conflicts can arise. Conflict partition scheduling addresses these issues by coordinating memory access, preventing data conflicts and resource contention.
Redis-based distributed locks can ensure that only one agent writes at a time. Advanced systems use conflict-free replicated data types (CRDTs) to allow concurrent updates without risking single points of failure. Additionally, tagging message metadata with agent-specific IDs (e.g., <session_id>-<agent_id>) helps prevent errors from one agent contaminating another's context.
In February 2026, the OMEGA memory system introduced a 12-stage pipeline incorporating features like deduplication, evolution checks, and conflict detection. This system achieved a 95.4% score on the LongMemEval benchmark, outperforming competitors such as Mastra (94.87%) and Zep/Graphiti (71.2%). Its success stemmed from a five-stage retrieval pipeline blending vector similarity, full-text search, and time-decay.
Benefits and Challenges
Benefits of Memory Partitioning
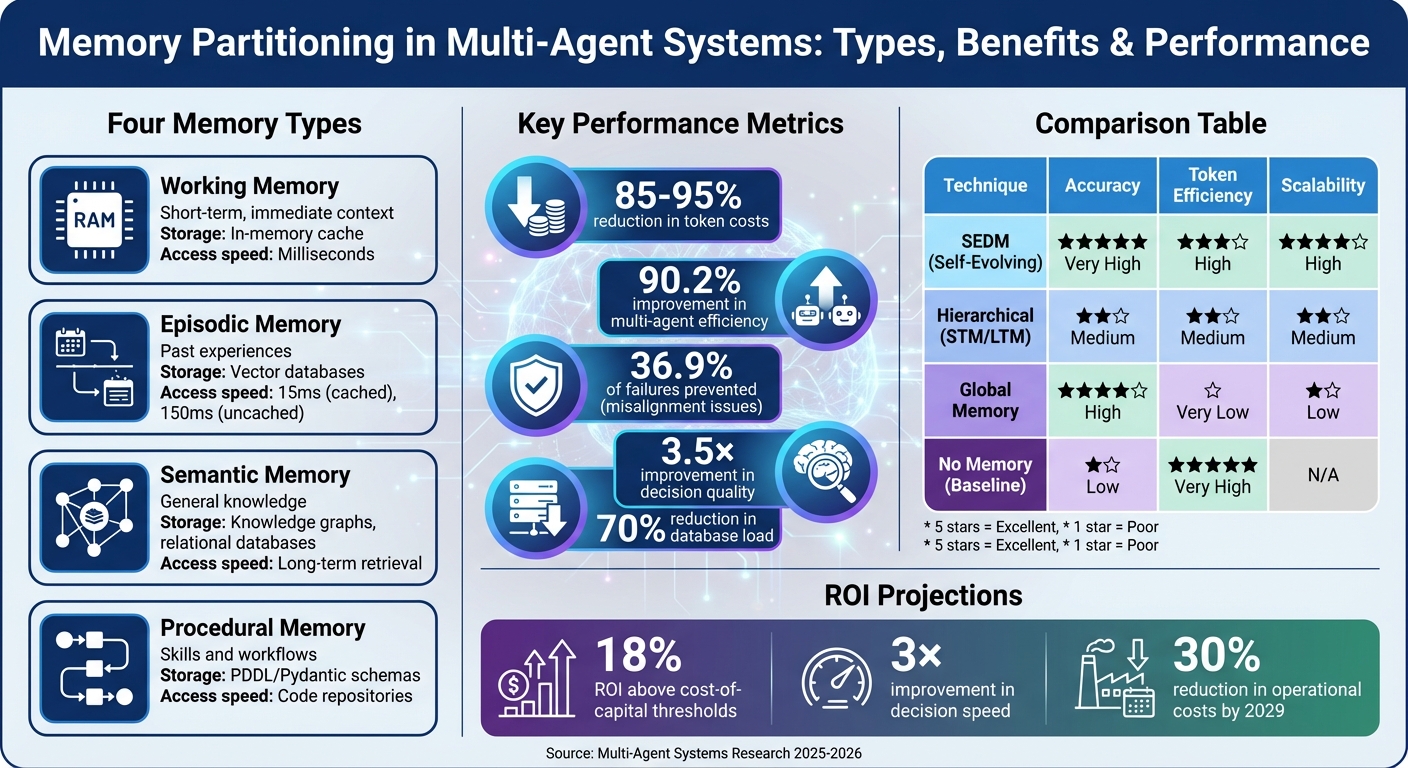
Memory partitioning offers several advantages that enhance system performance and efficiency. First, it boosts retrieval accuracy by isolating relevant data, reducing the need for agents to sift through irrelevant information. Second, it lowers storage and token overhead through methods like utility-based pruning, which can shrink vector database sizes by 40–60% within 30 days. Third, it supports scalability by offloading persistent data to external databases while keeping active reasoning processes in faster, local cache layers.
Real-world systems have demonstrated impressive performance improvements. For example, Anthropic's multi-agent research system saw a 90.2% improvement over single-agent baselines. The SEDM framework increased fact-verification accuracy from 57% to 66% on the FEVER benchmark while reducing token usage. Additionally, hierarchical memory setups have achieved 85–95% reductions in token costs for context management compared to less sophisticated approaches.
| Technique | Accuracy | Token Efficiency | Scalability |
|---|---|---|---|
| SEDM (Self-Evolving) | Very High | High (Optimized) | High |
| Hierarchical (STM/LTM) | Medium | Medium | Medium |
| Global Memory | High | Very Low (High Overhead) | Low |
| No Memory (Baseline) | Low | Very High | N/A |
Memory partitioning also enables heterogeneous team functionality, allowing smaller, specialized models to collaborate on complex tasks. By sharing memory, these models can avoid the inefficiency of requiring every agent to be a high-parameter generalist. According to Gartner, organizations adopting advanced memory engineering could achieve an 18% ROI above cost-of-capital thresholds, with a 3× improvement in decision speed and a 30% reduction in operational costs by 2029.
Common Challenges
Despite its advantages, memory partitioning presents several challenges. One major issue is information silos, where agents develop conflicting perspectives, leading to "context clash." Another is context poisoning, where errors stored in memory are repeatedly retrieved, amplifying mistakes over time. Privacy concerns also arise since shared memory layers often lack detailed access controls, which can expose sensitive data to unauthorized agents. Lastly, coordination overhead can cause delays, as multi-agent systems typically consume 15× more tokens than standard chat interactions due to frequent synchronization.
"In production, memory - not messaging - determines whether a multi-agent system behaves like a coordinated team or an expensive collision of independent processes." - Mikiko Bazeley, February 2026
The impact of these challenges is significant: interagent misalignment accounts for 36.9% of all multi-agent system failures. Specialized retraining of LLMs can result in a 40% drop in factual accuracy if memory and logic are not properly aligned. Early systems at Anthropic encountered inefficiencies, with 50 redundant sub-agents being spawned for simple tasks, as agents distracted each other with excessive updates.
| Challenge | Description | Mitigation Strategy |
|---|---|---|
| Context Rot | Declining performance as context length grows | Dynamic context pruning and hierarchical summarization |
| Information Silos | Agents lack visibility into peer progress | Shared "Consensus Memory" or "Whiteboard" patterns |
| Privacy Concerns | Risk of unauthorized access to sensitive data | Role-based access control (RBAC) and hierarchical data management |
| Coordination Overhead | High latency from frequent synchronization | Agent Cache Sharing protocols and token-budgeted routing |
How to Address Challenges
Addressing these challenges requires a combination of strategic solutions. First, selective forgetting can be implemented using a Recency-Relevance-Frequency (RIF) score to remove outdated or irrelevant memories. Second, hybrid retrieval methods - combining semantic vector search with keyword-based search (BM25) - ensure precise entities like code identifiers aren't overlooked by fuzzy embeddings. Third, maintaining semantic consistency is essential. This can be achieved by clearly defining memory access protocols (e.g., read-only vs. read-write) and using conflict-resolution policies like source ranking or consensus for critical data.
For privacy and coordination issues, hierarchical data management paired with role-based access control ensures agents only access data relevant to their roles. Packaging tasks into Self-Contained Execution Contexts (SCECs) allows for environment-free replay and offline validation of memory usage. Trust scoring can also help filter memory items by weighing factors like source reliability, corroboration from multiple agents, and recency.
Managing memory effectively resembles the use of virtual memory in operating systems. Techniques like "paging" move data between fast core contexts and slower archival storage as needed. To prevent memory bloat in long-running systems, verifiable write admission ensures that only memory items that pass A/B testing - proving their positive impact on task outcomes - are stored. Together, these strategies strengthen the efficiency and reliability of memory partitioning systems.
Implementing Memory Partitioning with Knowledge Plane
Knowledge Plane introduces a shared memory system designed specifically for engineering teams, streamlining how teams manage and access critical information.
Using Knowledge Plane for Shared Memory
Knowledge Plane brings together all your essential resources - code, documentation, tickets, and chats - into a single shared memory system accessible to AI agents. Instead of merely storing raw files, it extracts key facts and relationships, such as "Service A depends on Service B", while keeping the original documents in platforms like GitHub or Google Drive. Each piece of information is tagged with a source, owner, and timestamp, offering a complete audit trail. This ensures transparency and allows teams to track exactly where an AI agent derived its insights.
"Every piece of knowledge has a source, owner, and timestamp. You can trace exactly where the AI got its information and ship AI-assisted work to production with confidence." - Knowledge Plane
Memory partitioning is achieved through workspace isolation, dividing knowledge into distinct environments. Agents authenticate via API keys tied to specific workspaces, limiting their access to only the memory relevant to their role or team. Addressing the complexities of authorization, Mark Fogle, author of Clawtocracy, emphasizes:
"Authorization is an infrastructure problem, not a prompt problem. The moment you try to enforce access control at the prompt level, you've already lost"
Graph + Vector Memory for Context
Knowledge Plane employs a hybrid memory system that combines graph memory with vector embeddings, enabling more advanced reasoning than basic keyword matching. The graph memory stores detailed relationships such as depends_on, decided_by, and owned_by, allowing agents to navigate project data like seasoned team members. This setup not only helps agents understand what decisions were made but also identifies who made them, when, and how they connect to other elements.
Unlike conventional retrieval-augmented generation (RAG) tools that rely solely on dumping documents into vector stores, Knowledge Plane’s approach adds depth. By integrating semantic search with structured reasoning about dependencies, ownership, and timelines, it provides a richer, more contextual understanding of stored knowledge.
Deployment Steps
Engineering teams can implement Knowledge Plane in five straightforward steps:
- Connect: Link your repositories, documentation, and communication tools through APIs or the Model Context Protocol (MCP).
- Partition: Set up workspace isolation to segment memory by project or department, ensuring secure and scoped access for agents and teams.
- Automate: Use "Skills" to automatically fetch, reconcile, and update knowledge.
"Skills are scheduled jobs that automatically fetch, reconcile, and update your knowledge base. Instead of manually re-uploading docs when things change, skills detect drift between your sources and the stored knowledge, then update facts accordingly." - Knowledge Plane
- Integrate: Connect the memory layer with your AI tools, like Cursor or Claude, using MCP or standard HTTP APIs.
- Audit: Inspect the memory graph and its citations to confirm all information is up-to-date and traceable before deploying AI-assisted work.
Teams can choose between a managed cloud solution for quick deployment or a self-hosted option for full control over their data. Currently in private beta, Knowledge Plane is working with early adopters to refine its features and finalize pricing structures.
Conclusion
Summary of Benefits
Memory partitioning transforms isolated agents into cohesive teams. By adopting production-grade memory coordination, teams can achieve an 85% reduction in repeated work and a 3.5x boost in decision quality. Advanced memory management also significantly reduces context-related token usage - by 85% to 95% - tackling the coordination overhead that typically demands 15x more tokens than standard interactions.
A well-designed memory system organizes information across three layers: local context for single sessions, product-level memory for individual applications, and shared organizational memory for seamless cross-tool collaboration. This layered structure minimizes inter-agent misalignment, a key factor behind 36.9% of system failures. Memory-optimized agents outperform stateless ones, showing a 26% relative improvement on benchmark evaluations.
These figures underscore the importance of building a robust memory system as you plan future developments.
Next Steps for Engineering Teams
With these benefits in mind, engineering teams should begin by auditing their current memory architectures. Ensuring agents operate with a unified state rather than in isolation can lead to a 3x improvement in decision speed and a 30% reduction in operational costs by 2029.
Knowledge Plane offers a practical solution for teams looking to implement advanced memory systems. Its Layer 3 shared memory consolidates resources like code, documentation, tickets, and chats into a single, auditable source. Using a graph + vector architecture, it allows agents to analyze relationships - such as ownership and dependencies - while integrated Skills ensure context remains up-to-date. Currently in private beta, Knowledge Plane is working with early adopters to refine its capabilities. Deployment options include both managed cloud services and self-hosted solutions.
As the CEO of Mem0 aptly puts it:
"Every agentic application needs memory, just as every application needs a database."
- CEO of Mem0
With AI task durations doubling every seven months - from one-hour tasks in early 2025 to projected eight-hour workstreams by late 2026 - effective memory partitioning will be the key to moving beyond basic assistance and achieving true operational excellence.
FAQs
How do I decide what goes into working, episodic, semantic, and procedural memory?
Working memory is like your mental notepad - it temporarily stores active information, such as the details of a conversation or the steps of a task you're currently doing. Episodic memory, on the other hand, acts as a personal timeline, keeping track of specific events, like decisions you've made or noteworthy moments. Semantic memory is your mental encyclopedia, housing general facts and concepts you've learned over time. Finally, procedural memory is all about "how-to" knowledge - skills and processes, like riding a bike or typing on a keyboard. To determine which type of memory is at play, ask yourself: Is the information short-term (working), tied to a specific event (episodic), general knowledge (semantic), or related to a learned skill or process (procedural)?
How can teams prevent shared memory from being corrupted by a single agent’s mistakes?
To keep shared memory safe from corruption, teams can adopt several strategies. One effective approach is using consensus mechanisms, like PBFT-based semantic voting, which ensures that updates to the memory are approved by a fault-tolerant majority. Other methods include applying context-aware relevance assessments to filter out incorrect or irrelevant data and using decay functions to minimize the impact of outdated information. Additionally, reinforcement learning-based controllers can help selectively manage memory updates, preserving the integrity of shared memory in multi-agent systems.
What’s the simplest way to start partitioning private and shared memory in production?
The simplest approach to dividing private and shared memory in multi-agent systems is by using specialized memory infrastructure that handles state sharing automatically. This removes the need for custom synchronization processes. Shared memory can function as distributed state with built-in scoping capabilities, while NoSQL databases are ideal for managing scalable short-term memory. For long-term memory, layered models such as episodic and semantic memory offer a structured way to organize data, making them highly practical for use in production settings.