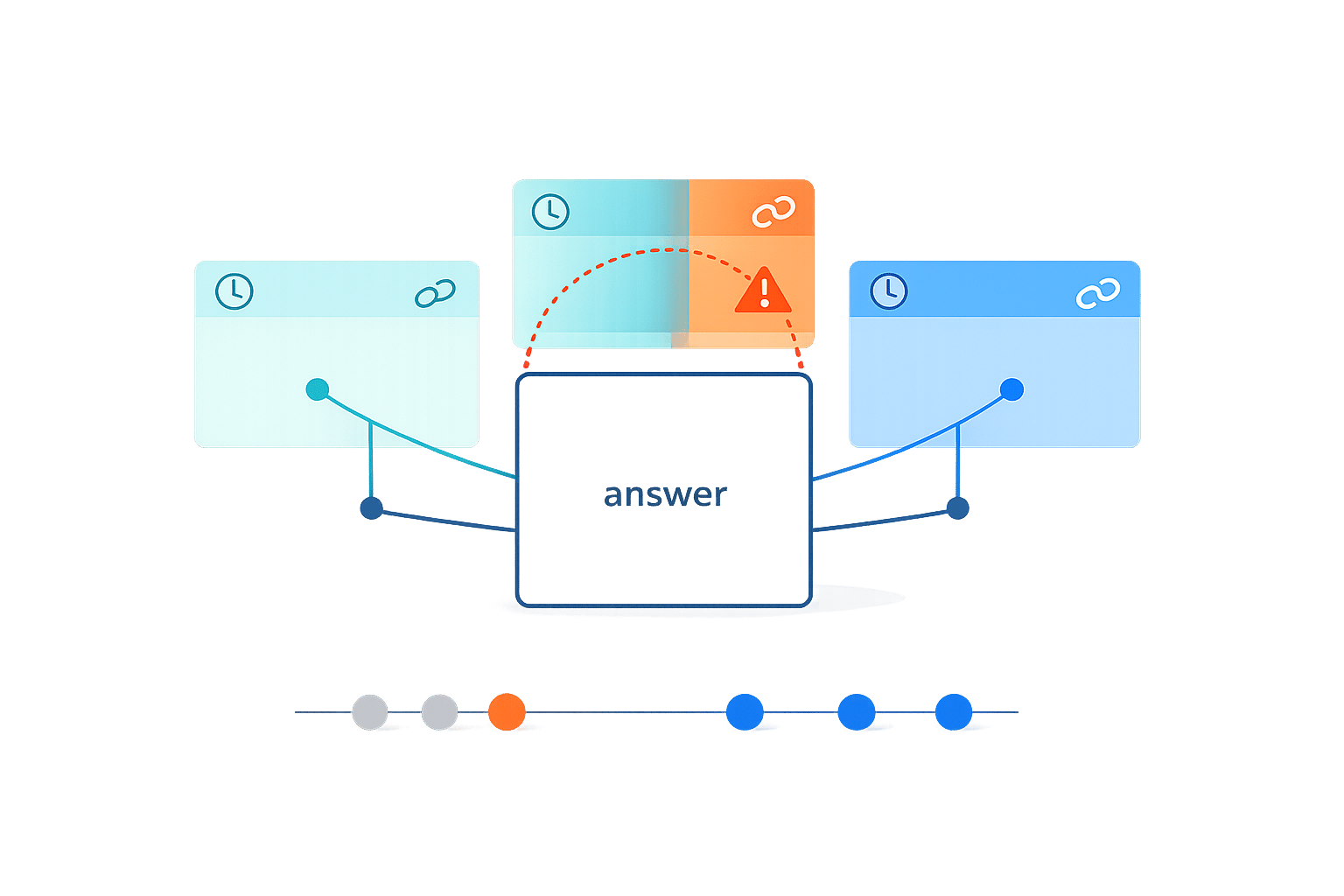
Traceable AI Answers: Detecting Knowledge Conflicts
Traceable AI Answers: Detecting Knowledge Conflicts
AI systems often fail by giving outdated or conflicting advice, especially in fast-changing environments like software development. Traceable AI answers solve this by linking responses to their sources, timestamps, and reasoning paths, ensuring accuracy and relevance. For example, tools like Agent Trace, introduced in January 2026, allow developers to track AI recommendations back to specific conversations or code changes.
Key Points:
- AI models frequently overwrite correct info with outdated data (60% of the time in shared memory systems).
- Knowledge conflicts come in four types: outdated training (CM), conflicting external sources (IC), internal contradictions (IM), and loss of critical details during summarization (compression conflicts).
- Techniques like residual stream probing, dual contrastive encoders, and attribution probing detect these conflicts with high accuracy (up to 90%).
Solutions:
- Graph-based systems map relationships between facts, improving context-aware decision-making.
- Automated audits and temporal knowledge graphs ensure stored information remains accurate over time.
- Tools like GitHub’s Copilot and Knowledge Plane have shown measurable improvements, such as a 7% increase in pull request merge rates.
Traceability in AI ensures reliable, consistent, and verifiable recommendations, making it indispensable for modern engineering workflows.
Consensus Algorithms and Conflict Resolution in Multi-Agent AI Systems
sbb-itb-1218984
Types of Knowledge Conflicts in AI Systems
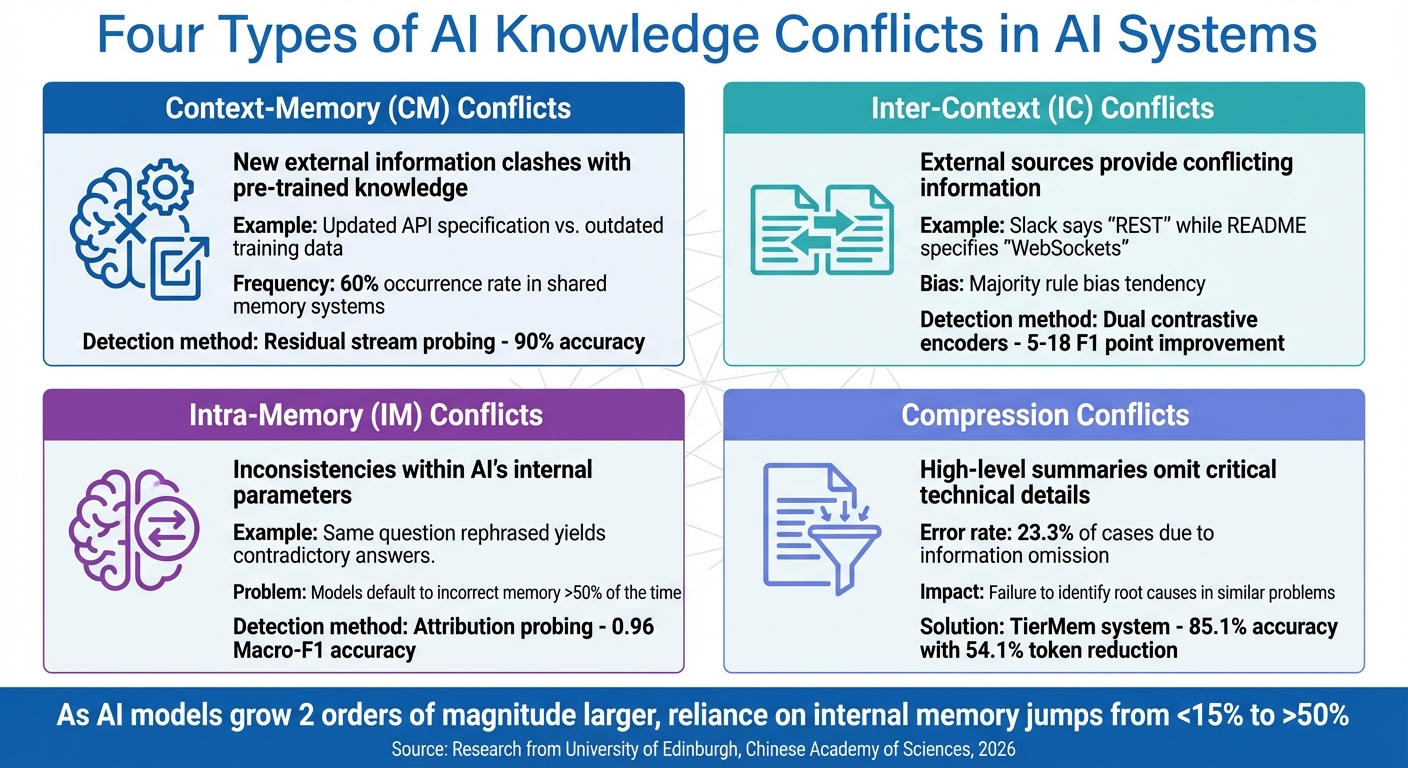
Four Types of AI Knowledge Conflicts and Their Detection Accuracy
Categories of Knowledge Conflicts
AI systems often encounter various challenges when processing and reconciling information, particularly when inconsistencies arise.
Context-Memory (CM) conflicts happen when new external information, such as an updated API specification, clashes with the AI's pre-trained knowledge. For example, if an authentication method is revised, the AI might still suggest the outdated approach based on older training data.
Inter-Context (IC) conflicts occur when external sources provide conflicting information. Imagine a Slack message stating, "We use REST", while an updated README specifies WebSockets. In such cases, the AI might rely on the more frequently mentioned data, revealing a tendency toward a "majority rule bias".
Intra-Memory (IM) conflicts are inconsistencies within the AI's internal parameters. For instance, rephrasing the same question might lead to contradictory answers because of how the model processes its internal knowledge.
A fourth type, compression conflicts, arises when high-level summaries leave out critical technical details. Studies suggest that compression can lead to errors in up to 23.3% of cases due to the omission of essential information.
These categories highlight the complexity of managing and resolving knowledge conflicts in AI systems.
Knowledge Conflict Examples
Real-world scenarios demonstrate the consequences of these conflicts. In February 2026, developer Jason Sosa introduced OMEGA, an MCP server memory system that achieved a 95.4% score on the LongMemEval benchmark. This system replaced conventional flat-file memory with a 12-phase pipeline, designed to detect inconsistencies between new and old information. For example, when a team switched from REST to WebSockets, OMEGA flagged the conflict, ensuring outdated recommendations were avoided. Such innovations illustrate the importance of advanced conflict detection in preventing the spread of incorrect or outdated information.
As AI models grow larger, these challenges become more pronounced. Research shows that when model size increases by two orders of magnitude, the reliance on internal memory (rather than external context) jumps from under 15% to over 50%. Additionally, models often exhibit a "Dunning-Kruger effect", where they lack confidence in accurate internal knowledge but over-rely on incorrect internal memory. In fact, they default to incorrect memory more than 50% of the time, even when accurate external evidence is available. Zhuoran Jin from the University of Chinese Academy of Sciences explains:
"Knowledge conflicts can ensnare RALMs in a tug-of-war between knowledge, limiting their practical applicability."
These conflicts become especially critical during incident response. For instance, if an AI compresses a previous bug fix into a vague summary, it might fail to identify the root cause when a similar problem arises. This loss of essential details during compression can have serious implications.
How to Detect Knowledge Conflicts
Conflict Detection Methods
Detecting knowledge conflicts in AI involves analyzing the model's decision-making process to identify when it struggles with conflicting information. Researchers have developed several methods to pinpoint these issues.
Residual stream probing looks at the intermediate layers of a language model to detect conflicts before they appear in the output. In January 2026, researchers at the University of Edinburgh found that conflict signals often emerge around layer 13 in models like Llama-3-8B. By training a logistic regression model on these activations, they achieved 90% accuracy in identifying conflicts. Yu Zhao, a researcher involved in the study, explained:
"LLMs can internally register the signal of knowledge conflict in the residual stream, which can be accurately detected by probing the intermediate model activations."
Dual contrastive encoders focus on distinguishing two questions: "Is this information relevant?" and "Is this information true?" The TCR (Transparent Conflict Resolution) framework, introduced in January 2026, uses this approach to generate three key signals - semantic similarity, factual consistency, and self-answerability. Tested across seven benchmarks, TCR improved conflict detection by 5–18 F1 points and reduced errors from misleading context by 29.3 percentage points, all while adding only 0.3% more parameters to the base model.
Attribution probing determines whether an AI's response is based on its internal training data or external context. Linear classifiers trained on hidden representations can identify the knowledge source with up to 0.96 Macro-F1 accuracy in models like Llama-3.1-8B and Mistral-7B. This is critical because mismatches - when the model relies on outdated internal knowledge instead of provided context - can increase error rates by up to 70%.
These methods become even more effective when paired with systems that provide clear traceability.
How Traceability Improves Detection
Traceability mechanisms enhance conflict detection by linking AI-generated answers back to their sources. Instead of relying on opaque memory systems, these approaches maintain explicit connections between summaries and raw data.
Provenance-linked hierarchies organize information into a two-tier structure where summaries are directly tied to their source documents. In February 2026, researchers introduced TierMem, a system tested on the LoCoMo benchmark. TierMem uses a "sufficiency router" to identify when summary-level evidence is insufficient and escalates to raw data when needed. This reduced input tokens by 54.1% and latency by 60.7%, while maintaining 85.1% accuracy. Qiming Zhu, one of the researchers, remarked:
"Any fixed-budget summary admits a worst-case query it cannot support with traceable evidence. These failures are not merely occasional summarization errors; they are structural risks of lossy, write-before-query compression."
Statement-level auditing breaks down AI responses into individual claims and verifies each one against its cited sources. In September 2025, Salesforce AI Research and Microsoft Research developed DeepTRACE, which uses "factual-support matrices" to ensure statements align with their sources. When tested on models like GPT-4.5/5, Perplexity, and Copilot, citation accuracy ranged from 40% to 80%, with unsupported statement rates reaching as high as 97.5% for debate-style queries.
Observational memory logs maintain a structured, append-only record of events, helping prevent contradictions or hallucinations. This approach ensures that AI agents don't contradict their past decisions or fabricate past events, making it easier to identify conflicts when new information clashes with prior actions.
How to Resolve Knowledge Conflicts
Resolution Techniques for AI Systems
Once conflicts are identified, AI systems need effective strategies to determine the correct information. Here are some key techniques:
Transparent Conflict Resolution (TCR) uses dual contrastive encoders to evaluate both relevance and factual accuracy while keeping the reasoning process traceable. This approach relies on verifiable sources to guide decision-making. In January 2026, researchers Hua Ye and Siyuan Chen tested TCR on the Wikidata-Conflict-5K dataset. By incorporating soft-prompt tuning with Signal-to-Noise Ratio (SNR) weighting, the system generated three critical signals: semantic similarity, factual consistency, and self-answerability. The results? A 21.4 percentage point improvement in recovering knowledge gaps and a 29.3 percentage point reduction in misleading-context overrides.
Knowledge Conflict Reasoning (KCR) focuses on structured reasoning paths to resolve conflicting contexts. Developed by Xianda Zheng and his team at the University of Auckland in August 2025, this framework employs Reinforcement Learning with Verifiable Rewards (RLVR) to prioritize logical consistency. By leveraging reasoning paths extracted from local knowledge graphs, KCR allowed smaller 7B-parameter models to outperform much larger 32B-parameter models in conflict resolution.
Conflict-Disentangle Contrastive Decoding (CD2) works by calibrating model confidence through a comparison of logits with and without external inputs. In February 2024, Zhuoran Jin and colleagues at the Chinese Academy of Sciences trained two types of language models: an "expert LM" for truthful answers and an "amateur LM" for misleading ones. Using contrastive decoding to maximize the difference between their outputs, the method improved Recall by 2.41% on the TriviaQA dataset.
SPARE (Steering Knowledge Selection) operates during inference by analyzing the residual stream - the intermediate layers where conflict signals emerge - and guiding the model toward the correct knowledge source. Research demonstrates that examining the residual stream of models like Llama-3-8B can identify conflicts with 90% accuracy at the 13th or 14th layer, even before the model generates an answer.
These techniques highlight how AI systems can be fine-tuned to manage conflicting information effectively. Next, let’s explore how graph-based methods enhance this process by mapping connections and timelines.
Using Graphs to Resolve Conflicts
Graph-based approaches offer a powerful way to resolve conflicts by explicitly mapping relationships between data points. Traditional vector search often overlooks dependencies, such as whether specific services have adopted a new authentication pattern or still rely on a legacy method.
Graphs excel by storing knowledge as a network of interconnected facts with clearly defined relationships like depends_on, decided_by, and owned_by. When conflicts arise, the system can traverse these connections to provide context-aware answers. For instance, if documentation recommends one authentication method but code repositories suggest another, a graph can pinpoint which services have transitioned and which haven’t. This ensures recommendations are precise and contextually grounded.
In January 2026, GitHub’s engineering team, led by Principal ML Engineer Tiferet Gazit, implemented an agentic memory system for GitHub Copilot. This system used just-in-time verification to enhance decision-making. For example, when the Code Review agent learned a logging convention ("app-YYYYMMDD.log" with Winston) from a pull request, it shared this information with the Coding Agent, which then applied the format to new microservices. This memory-sharing approach boosted PR merge rates from 83% to 90%.
Pattern consolidation adds another layer by clustering repeated decision traces into "meta nodes." These abstractions allow the system to go beyond simple precedent tracking, enabling it to predict the most effective resolution strategy for recurring scenarios. Instead of merely replaying past decisions, the system learns to anticipate and handle conflicts more proactively.
Traceable AI in Knowledge Plane
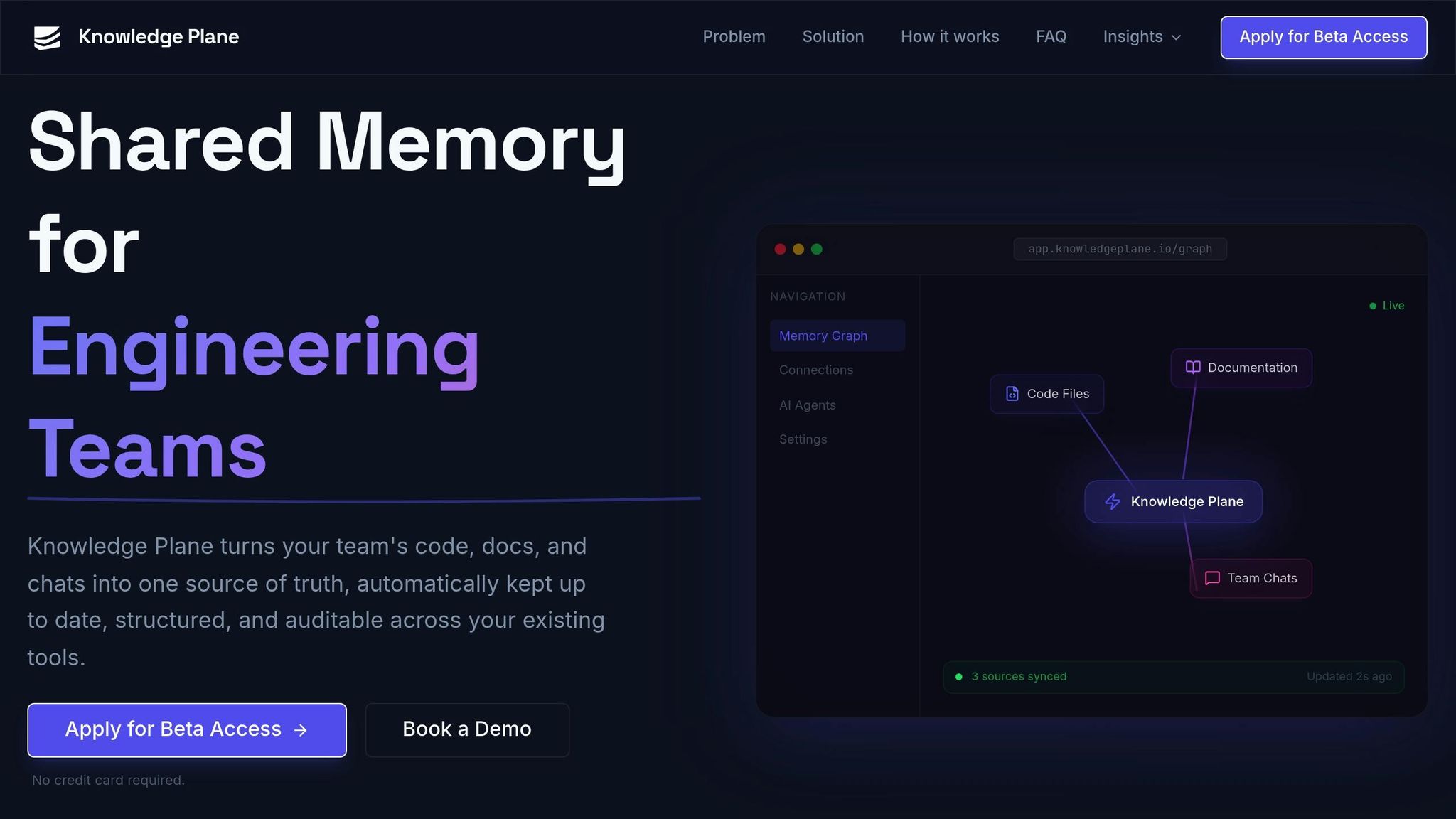
Graph + Vector Memory for Shared Context
The Knowledge Plane addresses knowledge conflicts by combining graph memory with vector embeddings, creating a structured network of interconnected and traceable facts. Unlike the typical RAG systems, which rely heavily on semantic search to find similar documents, the Knowledge Plane introduces a graph layer with defined relationships like depends_on, decided_by, and owned_by. This setup allows AI agents to go beyond surface-level searches, enabling them to trace decision chains and understand the broader context.
"Graph memory stores knowledge as a network of connected facts rather than isolated chunks... This lets AI agents traverse connections and understand context the way a senior team member would - following the chain of decisions, not just finding similar text." - Knowledge Plane
Each piece of knowledge is stored in a "knowledge card" that includes critical details like its source, owner, and timestamp. This level of attribution makes it easier for AI agents to detect and resolve conflicts. For example, the system can identify which team adopted a new authentication method, who made that decision, and when it happened.
To maintain this structured memory, automated audits are used to ensure all stored facts remain accurate and up-to-date.
Automated Audits and Conflict Resolution
To complement the graph-based context, the Knowledge Plane uses automated audits that continuously align stored facts with real-time source data. These audits are powered by "skills", which are essentially scheduled background jobs that reconcile and refresh the knowledge base. By doing so, the system can detect discrepancies across sources like Slack messages, GitHub pull requests, and internal documentation, ensuring that outdated information doesn't mislead the AI.
The system also employs a temporal knowledge graph, which tracks decisions over time. This temporal tracking allows the AI to differentiate between recent updates and older, potentially obsolete decisions. As a result, it avoids making recommendations based on outdated practices. Every query, update, and write is meticulously logged with user attribution and source tracking, creating a fully auditable trail of organizational knowledge.
Since it is MCP-native (Model Context Protocol), the Knowledge Plane integrates seamlessly with any AI agent or tool that supports open standards. This makes it easy for engineering teams to incorporate traceable AI-driven insights into their workflows.
Conclusion
For engineering teams aiming to make AI a reliable, production-ready tool, ensuring AI traceability is non-negotiable. This means having complete visibility into the source, approval status, and freshness of information. With such a system in place, every piece of knowledge - whether it's a code citation, a timestamp, or ownership details - comes with a clear, auditable trail.
The benefits of this approach are already evident. For instance, recent implementations have shown a 7% increase in pull request merge rates (rising from 83% to 90%) and a 2% improvement in positive feedback on automated code reviews. Principal ML Engineer Tiferet Gazit highlighted the importance of real-time verification:
"Information retrieval is an asymmetrical problem: It's hard to solve, but easy to verify. By using real-time verification, we gain the power of pre-stored memories while avoiding the risk of outdated or misleading information".
These results emphasize how traceability can reshape development workflows, making them more efficient and reliable.
But the impact of traceability goes beyond individual tasks. It ensures cross-agent consistency by allowing all agents - whether they're focused on code reviews, security, or documentation - to operate from the same verified knowledge base. For example, when one agent identifies a logging convention, that insight is instantly shared across the board, eliminating silos and ensuring that decisions made in one area are applied universally. This creates a seamless and unified workflow.
The technical advantages are equally compelling. Traceable AI frameworks not only enhance conflict detection (with gains of +5–18 F1 points) but also reduce misleading-context overrides by 29.3 percentage points and improve knowledge-gap recovery by 21.4 percentage points. And these improvements come at a low cost, requiring just 0.3% additional parameters and 0.3 GB of VRAM, making traceability a practical enhancement to existing systems.
For teams leveraging shared memory systems, traceability isn't just a nice-to-have - it's essential. Tools like Knowledge Plane make it possible to integrate code, documentation, and team communications into a single, auditable knowledge base. This approach not only boosts operational efficiency but also ensures that AI systems are robust and ready for production.
FAQs
What are traceable AI answers?
Traceable AI offers explanations for its responses by revealing the signals it uses to identify and manage knowledge conflicts. This transparency makes the decision-making process easier to understand and control. It ensures clarity and accountability, especially in systems that involve shared memory.
How can teams catch outdated or conflicting AI advice early?
Teams can stay ahead of outdated or conflicting AI advice by leveraging traceability and transparency mechanisms. For instance, tools like distributed tracing can map out reasoning paths and expose inconsistencies in real-time production environments. Additionally, frameworks like Transparent Conflict Resolution (TCR) provide a structured way to monitor and manage conflict detection, particularly in retrieval-augmented generation systems. This ensures AI-generated advice remains both accurate and dependable.
What does Knowledge Plane log to keep AI context auditable?
Knowledge Plane keeps a structured, up-to-date memory by logging information from code, documents, and team chats. This ensures that AI context remains traceable and auditable, providing a clear record of changes and connections within your shared knowledge system.
Related Articles