Shared Memory vs RAG for AI Context
Shared Memory vs RAG for AI Context
When it comes to AI tools retaining context, two approaches dominate: Shared Memory and RAG (Retrieval-Augmented Generation). Here's the key takeaway:
- RAG retrieves information from static knowledge bases, treating every query as independent. It's great for pulling facts but lacks the ability to learn or remember past interactions.
- Shared Memory acts like a dynamic "brain", storing, updating, and reasoning over information across sessions. It continuously learns and tracks relationships, making it ideal for workflows that require ongoing context.
Quick Overview:
- RAG: Best for retrieving static, document-based knowledge.
- Shared Memory: Ideal for tracking evolving information, ownership, and decisions over time.
Why it matters: Shared Memory reduces errors caused by incomplete context, handles historical data better, and supports complex workflows like incident response or team collaboration. Meanwhile, RAG excels in retrieving up-to-date facts from external sources.
Key Difference: RAG is static and stateless; Shared Memory is dynamic and stateful.
For engineering teams, combining both systems can deliver the best results: RAG for external facts and Shared Memory for internal, evolving context.
Stop Using RAG as Memory - Daniel Chalef, Zep
sbb-itb-1218984
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a system design that allows a large language model (LLM) to pull information from external knowledge sources before crafting a response. Instead of relying entirely on pre-trained data, the model taps into external, up-to-date information - essentially acting as its "non-parametric memory."
This approach solves a major limitation of standard LLMs: outdated or incomplete knowledge. Since LLMs are trained on a fixed dataset, they often lack awareness of recent developments or proprietary data. RAG gets around this by separating knowledge from the model itself. This means it can access real-time or domain-specific information without requiring costly retraining.
By 2024, 86% of organizations had integrated RAG frameworks into their LLMs, a sharp increase from 31% in 2023. The market for RAG solutions reached $1.2 billion in 2024 and is expected to grow to $11 billion by 2030, with a compound annual growth rate of 49.1%. Companies using RAG report significant benefits, including a 60–80% drop in hallucinations and a threefold improvement in the accuracy of domain-specific answers.
How RAG Works
RAG uses a four-step process to convert static documents into dynamic, searchable knowledge:
-
Indexing the Knowledge Base:
Documents are broken into small, tokenized chunks and transformed into numerical vectors that capture their meaning. These vectors are stored in a specialized vector database. -
Semantic Search:
When a query is submitted, it’s also converted into a vector. This enables the system to retrieve relevant information, even if the phrasing differs from the original text. -
Context Augmentation:
The retrieved chunks are combined with the user's question to create a single, context-rich prompt. This ensures the LLM has all the relevant details when generating a response. -
Grounded Response Generation:
The LLM uses this enhanced prompt to craft an answer, often including citations to the original sources. This transparency helps users verify the information and builds trust in the system.
Modern RAG systems often pair vector similarity searches with traditional keyword searches (like BM25) to balance semantic understanding with technical precision. Some systems also use cross-encoder models to re-rank search results, boosting accuracy even if it slightly increases response time (by 50–200 ms).
This structured process ensures that responses are both accurate and grounded in verifiable data.
Use Cases for RAG
Thanks to its ability to deliver accurate and traceable answers, RAG has become a go-to solution for a variety of applications.
In customer support, RAG-powered chatbots extract answers from documentation and company policies. For example, DoorDash uses RAG to pull relevant support articles when drivers or customers submit inquiries.
Enterprise knowledge management is another area where RAG shines. In 2025, the Solana Foundation introduced a RAG-based "Ask AI" tool using Inkeep's platform. This allowed the foundation to improve developer support by making hard-to-find documentation easily searchable, delivering measurable returns without increasing staff.
Healthcare and finance also benefit from RAG's capabilities. It enhances diagnostic accuracy in medical applications by up to 20% and reduces ticket resolution times in customer support by 28%.
RAG is particularly effective for managing large volumes of static information - documents that don’t change often but need to be easily searchable. Its ability to provide citations and audit trails makes it especially valuable in regulated industries where traceability is a must.
What Is Shared Memory?
Shared memory is a system designed to help teams by enabling AI to store, update, and reason over interconnected data across an organization. Think of it as a constantly evolving system that mirrors team dynamics in real time. Unlike Retrieval-Augmented Generation (RAG), which operates more like a static filing cabinet of documents, shared memory acts as a dynamic, read-and-write "organizational brain." It doesn't just search for answers in documents - it actively tracks workflows, decisions, and relationships, adapting as new information comes in.
Here's the key distinction: while RAG simply retrieves information to answer questions, shared memory connects the dots between knowledge, updating itself to reflect changes in workflows or team interactions. For example, it can understand dependencies like "Service A depends on Service B" or ownership details such as "Alice owns the authentication module." This is made possible through a combination of graph memory (storing typed relationships) and vector embeddings (enabling semantic search). Together, these tools allow shared memory to provide deeper insights than a simple document search ever could.
Shared memory also captures the history and reasoning behind decisions. This means AI agents across different departments can work with a unified, up-to-date context. By addressing the limitations of traditional search systems, shared memory creates a foundation for managing complex workflows, as described in the technical details below.
How Shared Memory Works
Shared memory systems rely on five interconnected layers: Encoding, Storage, Retrieval, Knowledge Graph, and Lifecycle Management. These layers transform unstructured data - like conversations, code commits, or documentation - into structured, queryable knowledge.
The write path is where shared memory takes a major leap from traditional systems. When new information comes in, the system extracts key facts, resolves entities (e.g., linking "the CTO" to "Alice"), and reconciles any conflicts. For instance, if a developer says, "we switched from MySQL to PostgreSQL", the system updates the knowledge graph to reflect this change.
Storage combines multiple methods. Vector stores handle immutable reference data, such as best practices and documentation, while graph databases track active, evolving truths - like project statuses, task assignments, and system dependencies. This separation ensures that static reference material doesn’t get mixed up with constantly changing information.
For retrieval, shared memory uses hybrid techniques that include semantic matching, recency decay, and importance weighting. This ensures critical details - like "the production database is PostgreSQL 15" - aren’t buried under outdated or less relevant data. The system also supports specialized queries, such as temporal searches (e.g., what happened last week), entity-based searches (e.g., everything related to the authentication service), and pattern recognition (e.g., recurring issues).
Lifecycle management is what transforms a database into a memory system. By applying decay functions and consolidation techniques, shared memory prioritizes current and frequently accessed data. As Shodh Systems puts it:
"If a system does encoding, storage, and retrieval but not management, it's a database. Management is what makes it memory".
To keep everything up to date, the system uses automated "Skills." These are scheduled jobs that monitor code repositories, documentation, tickets, and team chats, ensuring the knowledge graph stays current without manual input. At the same time, it maintains full traceability, recording how information evolves over time. This approach enables a wide range of practical applications for engineering teams.
Use Cases for Shared Memory
Shared memory is particularly effective in situations where context needs to persist across time, teams, and tools. Its layered architecture - combining graph relationships, vector search, and lifecycle management - supports a variety of real-world scenarios.
One standout example is ensuring organizational continuity during team transitions or long-term projects. Take the case of Ema's Agentic Employee system in January 2026. On January 12, the AE-Sales team approved a 15% discount for a prospect named Acme to close a deal before the quarterly deadline. Just two days later, when Acme filed an urgent support ticket about a delivery delay, the AE-Support team accessed the shared memory. It recognized Acme as a high-priority client and autonomously upgraded the support level, authorizing overnight shipping to protect the original sales intent.
Another critical use is dependency tracking. Engineering teams use shared memory to map out service dependencies, ownership assignments, and architectural decisions. For example, when a developer asks, "Who owns the authentication service?" or "Which services depend on the user database?" the system can traverse the knowledge graph to provide accurate, up-to-date answers.
Collaborative workflows also benefit greatly from shared memory. Consider customer service interactions, which can generate thousands of tokens per conversation. For users with extensive histories - say, 100 past conversations - this could balloon to over 400,000 tokens, far exceeding the limits of most context windows. Shared memory solves this by maintaining a structured, accessible history that multiple agents can reference without needing to reload entire conversation logs.
When engineering teams undertake major technical migrations, shared memory updates the knowledge graph to reflect current decisions while preserving the rationale behind earlier ones. This prevents AI from suggesting outdated solutions based on obsolete documentation.
Finally, shared memory helps preserve tribal knowledge. If a senior developer leaves, the insights they contributed - through code reviews, design discussions, or incident post-mortems - remain accessible. This ensures the organization retains a clear understanding of system architectures and past decisions, even as team members come and go.
Key Differences: Shared Memory vs RAG
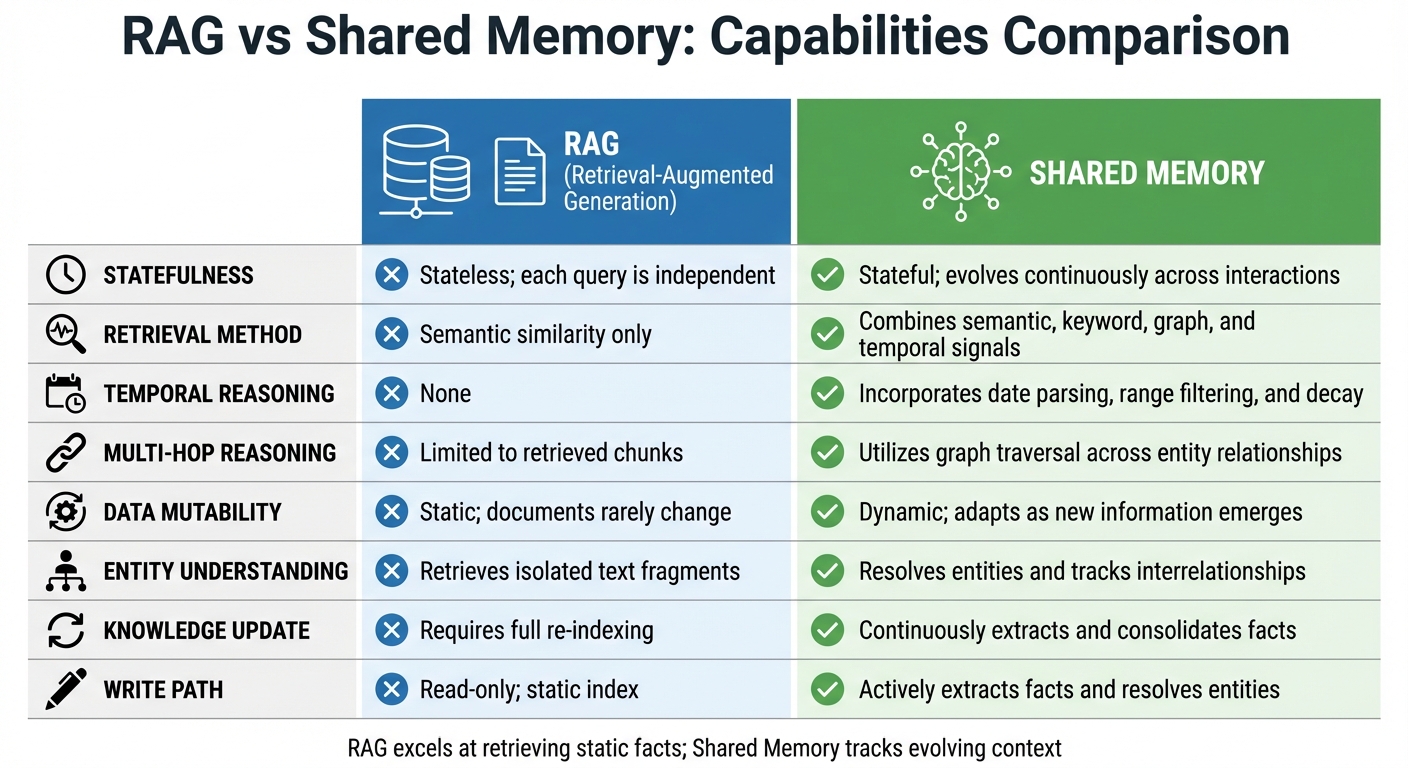
Shared Memory vs RAG: Key Differences and Capabilities Comparison
The main difference lies in how they handle context. RAG (Retrieval-Augmented Generation) treats each query as a standalone event, pulling relevant documents from a fixed database without remembering past interactions. On the other hand, shared memory systems build on prior knowledge, maintaining a dynamic understanding of relationships and history across sessions, tools, and teams.
Another notable difference is how they handle updates. RAG operates on a read-only system - documents are indexed once and queried repeatedly. Shared memory, however, has an active write path, allowing it to extract and consolidate facts in real time. For example, it can link references like "the CTO" and "Alice" to the same entity, updating its knowledge as new data comes in. This makes shared memory better equipped to handle changing information and resolve contradictions, whereas RAG might present outdated and current facts side by side, leading to potential confusion.
The way these systems retrieve information also sets them apart. RAG relies solely on semantic vector search to find relevant content. Shared memory, in contrast, uses multiple signals - combining semantic search with keyword matching, time-based recency, and graph traversal. This approach enables multi-hop reasoning, like connecting a pull request to an incident and then to a specific developer, which is beyond RAG's capabilities.
Finally, their knowledge structures differ significantly. RAG works with flat vector embeddings of document chunks, while shared memory uses temporal knowledge graphs that map connections between entities, events, and decisions. This allows shared memory to answer complex relational queries like "Who owns the authentication service?" rather than merely retrieving documents that mention certain keywords.
Comparison Table: Capabilities
| Capability | Retrieval-Augmented Generation (RAG) | Shared Memory Systems |
|---|---|---|
| Statefulness | Stateless; each query is independent | Stateful; evolves continuously across interactions |
| Retrieval Method | Semantic similarity only | Combines semantic, keyword, graph, and temporal signals |
| Temporal Reasoning | None | Incorporates date parsing, range filtering, and decay |
| Multi-hop Reasoning | Limited to retrieved chunks | Utilizes graph traversal across entity relationships |
| Data Mutability | Static; documents rarely change | Dynamic; adapts as new information emerges |
| Entity Understanding | Retrieves isolated text fragments | Resolves entities and tracks interrelationships |
| Knowledge Update | Requires full re-indexing | Continuously extracts and consolidates facts |
| Write Path | Read-only; static index | Actively extracts facts and resolves entities |
Limitations of RAG for AI Context
RAG (Retrieval-Augmented Generation) is great at pulling information from static documentation, but it falters when the context changes. RAG processes each query in isolation, without any way to track or adapt to evolving context. This creates what researchers call the "Temporal Event Horizon," a major challenge for retaining and utilizing historical context.
One key issue is how RAG systems handle older information. They use an exponential decay mechanism to prioritize recent documents, which effectively erases older data from the AI's "memory." For example, in controlled tests, traditional RAG systems managed only 12.4% recall on code older than six months, while memory-aware systems achieved a much higher 88.7% recall. Documents that are two years old might get a recency score as low as 0.000000024, making them virtually invisible to the AI, even if they’re still relevant. As a result, 88% of relevant historical documents were completely overlooked in standard RAG setups.
Another limitation stems from how RAG chunks documents into smaller segments for embedding. While chunking makes retrieval easier, it also breaks important relationships within the text. For instance, splitting a document can sever the link between a contract clause and its definitions or policies. As noted in The Context Graph:
Chunking treats documents as bags of passages. Decisions require structured relationships between those passages - relationships that chunking systematically destroys.
RAG also struggles to differentiate between what’s similar and what’s actually relevant. Its reliance on semantic similarity means it might retrieve a superseded policy with better keyword overlap instead of the current version. Semantic similarity alone doesn’t guarantee contextual relevance. This can lead to "context pollution", where outdated and current information mix, confusing the AI.
Finally, RAG’s stateless design is a major drawback. It doesn’t learn from past interactions, forcing the AI to repeatedly search external sources rather than building on prior experiences. Michael Fauscette, Founder & CEO of Arion Research, sums this up well:
Knowledge is knowing what the documentation says. Wisdom is remembering that the last three times you followed that documentation, step four didn't work in your production environment.
Without the ability to retain and apply lessons, RAG systems miss opportunities to improve efficiency and accuracy over time.
Benefits of Shared Memory for Engineering Teams
Shared memory systems offer a fresh approach to overcoming the limitations of Retrieval-Augmented Generation (RAG) by continuously updating context to address the dynamic needs of engineering teams. While RAG focuses on retrieving what documents explicitly state, shared memory shifts the focus to meeting user-specific requirements. This change is reshaping how engineering teams interact with AI.
One of the standout advantages is automatic updates. Shared memory systems use event-driven ingestion to refresh context without requiring manual input. For instance, when a pull request is merged, a deployment is completed, or documentation is updated, these changes are seamlessly integrated into the memory layer. This eliminates the need for manual re-indexing and ensures that data remains current. The system’s refined write path extracts critical facts from unstructured data, resolves entities (such as linking Slack users to their GitHub contributions), and reconciles conflicts to create a unified source of truth. This dynamic updating process also enhances traceability, aiding in decision-making.
Temporal knowledge graphs further enhance traceability by capturing when decisions are made and when they are replaced. This allows the AI to differentiate between current architecture and outdated patterns. For example, during incident debugging, the system can link errors to a specific deployment, the relevant pull request, and the engineer responsible - providing a clear, traceable context.
In collaborative workflows, shared memory shines by connecting relationships across various tools. For example, it can identify that a name mentioned in a team chat is the same individual who owns a critical service or recently authored a pull request. By resolving these cross-tool connections, shared memory enables AI to understand ownership, dependencies, and team preferences with greater accuracy. This systematic approach to context improves enterprise AI accuracy by 35–60%, addressing the fact that over 70% of errors in modern LLM applications stem from incomplete context.
Here’s a quick look at how shared memory outperforms RAG in common engineering scenarios:
Comparison Table: Use Cases
| Use Case | RAG Approach | Shared Memory Approach |
|---|---|---|
| Onboarding New Engineers | Retrieves static setup documentation; may miss recent changes | Automatically pulls up-to-date setup guides and flags recent changes to key components (e.g., database schemas) |
| Incident Response | Finds log fragments mentioning an error code | Correlates errors with specific deployments, pull requests, and the responsible engineer |
| Architecture Decisions | Provides generic pros and cons of technologies | Understands the existing tech stack, team preferences, and references prior internal decisions |
| Knowledge Evolution | Struggles with versioning; may retrieve outdated policies | Tracks when new policies replace old ones and maps progression over time |
| Ownership Tracking | Offers limited insight into team roles and responsibilities | Identifies team leads, review policies, and dependencies by navigating organizational knowledge graphs |
These capabilities illustrate how shared memory systems transform workflows, making them more efficient, accurate, and context-aware. By addressing common pain points in engineering processes, shared memory delivers practical solutions that go beyond the limitations of traditional RAG methods.
When to Choose Shared Memory Over RAG
Shared memory shines when your AI needs to learn, adapt, and build on past interactions. It's ideal for applications like AI companions, personalized tutors, or team copilots - situations where the value grows through ongoing, meaningful interactions. On the other hand, RAG (Retrieval-Augmented Generation) works best for tasks like documentation assistance or enterprise search, where the focus is on retrieving facts from a static knowledge base. This distinction becomes critical when historical context and continuous adaptation are key to decision-making.
A clear example of shared memory's strength is when corrections or rules need to persist. Imagine a user instructing, "Always route orders over $50,000 through legal." Shared memory ensures this rule is remembered and applied in future interactions, whereas RAG's static nature wouldn't retain such directives.
"RAG answers 'What does this document say?' Memory answers 'what does this user need?'"
– Fimber Elemuwa, Engineering, Mem0
Temporal reasoning is another area where shared memory is essential. If your AI needs to answer questions like "What has changed since last week?" or identify shifts in patterns over time, shared memory provides the dynamic updates needed. This evolving capability sets it apart from RAG, positioning shared memory as a continuously growing, organizational brain.
For engineering teams, shared memory proves invaluable when linking complex, interconnected information. For example, connecting a Slack mention to the engineer responsible for a service or associating it with a pull request. A graph-based shared memory approach naturally handles these relationships, making it indispensable for tasks like incident response, onboarding, or architectural decisions. Platforms like Knowledge Plane demonstrate how shared memory can seamlessly integrate elements like code, documentation, tickets, and team chats into one constantly updated source of truth.
Switching from prompt engineering to context engineering can significantly improve results. Accuracy increases by 35–60%, addressing the fact that over 70% of errors are caused by incomplete or poorly structured context.
Combining Shared Memory and RAG
The smartest AI systems don’t make you pick between shared memory and Retrieval-Augmented Generation (RAG) - they bring the two together. In a hybrid setup, the system first retrieves team-specific context from shared memory, then pulls in external facts using RAG. These are merged, and any new insights are written back into memory. This "Retrieve-Merge-Generate-Write" loop ensures the AI has both the broad knowledge it needs and the specific details about your team's decisions and preferences.
"The future isn't about choosing between RAG and memory layers - it's about combining them to create AI systems that are both knowledgeable and personal."
– Caura
This combination delivers noticeable efficiency gains. Memory-first architectures are particularly effective because the system checks its internal memory first before running more resource-intensive RAG queries. This reduces API costs, cuts down on latency, and avoids repeated explanations - saving professionals over 5 hours a week on average. When external information is retrieved through RAG, the AI can enrich its searches using contextual query expansion, adding relevant terms and entities from previous interactions automatically.
To make this work, information placement and structured tagging are critical. The "Lost in the Middle" issue - where key details get buried in the middle of a context window - can be avoided by positioning important facts at the beginning or end and tagging them with labels like <retrieved_knowledge> or <past_decisions> to clarify their origin. Pairing this with reflection loops, where the AI reviews completed tasks to extract useful patterns, allows for ongoing improvement.
For engineering teams, this hybrid approach is already being applied. Platforms like Knowledge Plane combine graph and vector memory with scheduled updates (called Skills) to keep the AI up-to-date on code, documentation, tickets, and team discussions. At the same time, the system can retrieve external technical knowledge when needed. This means the AI can answer questions like, "What does the API documentation say?" (RAG) and "Why did we choose this architecture pattern last month?" (shared memory). By blending these capabilities, the AI provides richer context, improving decision-making and streamlining workflows for engineering teams.
Conclusion
The discussion above highlights how different systems handle AI context, each with its own strengths. RAG operates as a stateless, document-focused tool that retrieves isolated facts from a database of information. In contrast, shared memory functions more like a dynamic brain, retaining team decisions, tracking contextual changes, and understanding relationships over time.
For engineering teams managing complex workflows, shared memory offers a crucial advantage: it provides temporal awareness and tracks evolving knowledge and dependencies. It can also reason through sequences and relationships, such as ownership or task dependencies. This is especially important given that over 70% of errors in modern large language model applications are caused by incomplete or poorly structured context.
Michael Fauscette, CEO & Chief Analyst at Arion Research, captures this distinction perfectly:
"RAG provides knowledge. Agents require wisdom. Knowledge is knowing what the documentation says. Wisdom is remembering that the last three times you followed that documentation, step four didn't work."
– Michael Fauscette
By systematically managing context and integrating memory systems, enterprises can improve AI accuracy by 35–60%. Additionally, incorporating shared memory boosts faithfulness metrics in multi-step Q&A by 42%. These improvements stem from shared memory’s ability to maintain session continuity and intelligently phase out outdated information - something static RAG systems simply cannot achieve.
For teams developing AI agents that need to grasp not just how a codebase functions but also the reasoning behind architectural decisions and ownership of components, shared memory is indispensable. Tools like Knowledge Plane demonstrate how shared memory can turn fragmented team knowledge into a cohesive, evolving system. By combining graph and vector memory with automated updates, it ensures AI context remains fresh, structured, and auditable within existing workflows. This approach underscores why memory-first strategies are becoming essential for engineering teams.
FAQs
When should I use shared memory instead of RAG?
Shared memory is perfect when you need to keep track of ongoing interactions, preferences, or organizational context in real time. Unlike Retrieval-Augmented Generation (RAG), which pulls in static information only when needed, shared memory continuously updates and evolves. This makes it an excellent choice for tasks that require long-term context awareness, such as personalized assistance or managing knowledge. It’s especially useful when you need to retain and work with information that changes and grows over time, like tracking relationships, decisions, or workflows.
What data should go into shared memory vs RAG?
Shared memory works best when dealing with structured and ever-changing information, such as relationships, ownership, or dependencies. It’s particularly suited for maintaining long-term context and reasoning through complex, interconnected data. On the other hand, RAG (Retrieval-Augmented Generation) is designed for retrieving static knowledge from external sources - think stable documents or product details - to provide answers to specific queries. Unlike shared memory, RAG isn’t built to handle dynamic relationships or knowledge that requires constant updates.
How do you keep shared memory accurate over time?
To keep shared memory accurate, it's crucial to use persistent storage for saving key details, preferences, and insights across sessions. Regular updates are essential to keep the information relevant - this can be managed through methods like reinforcement or decay. Additionally, the data should always be well-organized and easy to review. Tools such as Knowledge Plane can help by integrating code, documents, tickets, and chats into a structured, continuously updated memory. This setup enables better reasoning by mapping relationships like ownership and dependencies.