RAG vs Active Memory: AI Validation Explained
RAG vs Active Memory: AI Validation Explained
Which system should you choose for AI validation? It depends on your needs. Retrieval-Augmented Generation (RAG) works well when you need quick, accurate answers from static, unchanging data like manuals or policies. Active memory, however, is ideal for environments where data evolves constantly, like engineering workflows or dynamic codebases. It learns, updates, and reasons in real time, making it a better fit for managing complex, shifting information.
Key Takeaways:
- RAG: Pulls data from a static library for precise, source-based responses. Best for stable, factual knowledge.
- Active Memory: Continuously updates and links information across interactions. Best for dynamic, evolving contexts.
- Hybrid Approach: Combines RAG for static knowledge and active memory for dynamic workflows to balance consistency and flexibility.
Quick Comparison:
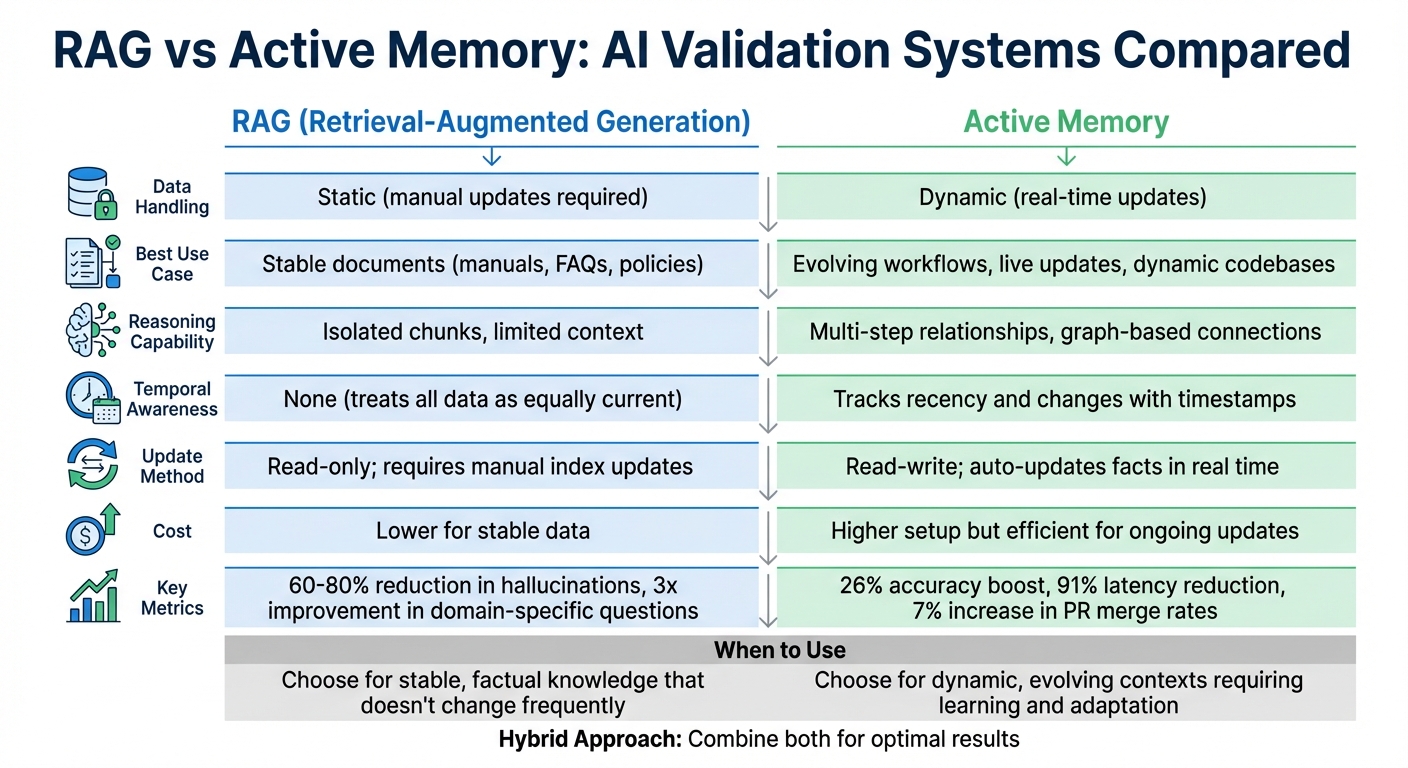
| Feature | RAG | Active Memory |
|---|---|---|
| Data Handling | Static (manual updates) | Dynamic (real-time updates) |
| Use Case | Stable documents (manuals, FAQs) | Evolving workflows, live updates |
| Reasoning | Isolated chunks | Multi-step relationships |
| Temporal Awareness | None | Tracks recency and changes |
| Cost | Lower for stable data | Higher setup but efficient for updates |
Both systems solve different problems. Choose RAG for stable data and active memory for dynamic, real-time needs.
RAG vs Active Memory: Feature Comparison for AI Systems
Agent Short Term vs Long Term Memory vs RAG Explained Simply!
sbb-itb-1218984
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a method that improves AI responses by pulling relevant documents from a knowledge base before generating an answer. Instead of relying solely on pre-trained data, RAG retrieves information first and then uses it to craft a response.
Paolo Perrone from The AI Engineer describes it well:
"RAG is an open-book exam for AI. Instead of answering from memory, the system retrieves relevant documents first, then generates an answer grounded in what it actually found."
This technique has become a cornerstone of modern AI applications. By 2025, about 60% of production AI systems are expected to use RAG. For engineering teams managing constantly changing codebases or documentation, RAG provides a way to keep AI assistants updated without the high costs of retraining models.
How RAG Works
The RAG process involves three main steps:
- Indexing: Documents are broken into smaller chunks (300–1,024 tokens) and converted into numerical vector embeddings that represent their meaning. These embeddings are stored in a vector database, such as Pinecone or Weaviate.
- Retrieval: When a user submits a query, the system converts it into a vector and performs a similarity search to find the most relevant document chunks. This often involves combining dense vector search (focused on meaning) with sparse retrieval methods like BM25 (focused on keyword matching) using techniques like Reciprocal Rank Fusion for better precision. This is particularly helpful for technical terms and acronyms.
- Augmentation and Generation: The retrieved chunks are added to the AI model's prompt as context. The model then generates a response based on this information rather than relying solely on its training. Some advanced systems also use cross-encoder models to re-rank the retrieved results, ensuring the most relevant data appears at the beginning or end of the prompt. This is crucial because large language models (LLMs) tend to focus more on information at the start and end of a prompt, often neglecting the middle.
Benefits of RAG
RAG offers clear advantages, especially for engineering teams:
- Reduced hallucinations: By grounding responses in actual documents, RAG lowers hallucinations by 60–80%.
- Improved accuracy: It delivers a 3x improvement in answering domain-specific questions.
- Real-time updates: When documentation or policies change, you can simply update the index instead of retraining the model. This makes RAG far more cost-efficient than fine-tuning, which requires significant compute resources and expertise.
- Traceability: RAG systems can point to specific source documents, making it easier to verify AI outputs.
For example, in 2024, Harvey AI partnered with PwC to create a Tax AI Assistant using RAG. This system indexed legal databases, case law, and regulations across 45 countries. In user evaluations, 91% of tax professionals preferred the RAG-based assistant over ChatGPT due to its better accuracy and ability to reference sources.
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Knowledge Update | Real-time; update the index | Requires retraining on new data |
| Source Attribution | High; cites specific chunks | Low; knowledge embedded in weights |
| Primary Use Case | Factual grounding | Adopting specific styles |
| Cost | Lower (pay-per-query/embedding) | Higher (training compute/expertise) |
Limitations of RAG
While RAG shines in many areas, it has notable shortcomings:
- Statelessness: Each query is treated independently. RAG cannot update, overwrite, or delete entries based on interactions.
- Temporal issues: RAG lacks a sense of recency or sequence. For example, it might struggle to differentiate between a decision made last week and one from last year. This can lead to "context pollution", where outdated and current information are retrieved together.
- Limited reasoning: RAG struggles with multi-hop reasoning - connecting dots across multiple documents or sessions. For instance, it might fail to link a system outage to a deployment change mentioned in an earlier interaction.
As shodh-memory.com puts it:
"RAG is the right tool when you have static knowledge... RAG is the wrong tool when you need personalization, learning, or proactive context."
What is Active Memory?
Active memory is a dynamic system designed to learn, update, and reason about relationships in real time. Unlike Retrieval-Augmented Generation (RAG), which functions as a read-only search engine, active memory operates like a read-write brain. It extracts facts, resolves contradictions, and keeps insights up-to-date and actionable.
The key difference lies in their focus. RAG answers, "What do these documents say?" Meanwhile, active memory focuses on, "What does this user or organization know and need right now?" This shift from static information retrieval to dynamic learning makes active memory especially useful for engineering teams handling ever-changing codebases, dependencies, and technical decisions. Let’s dive into its core features to understand how it works.
Core Features of Active Memory
Active memory systems combine graph and vector storage to manage both semantic understanding and relationship mapping. The graph structure maps connections between entities - like which engineer owns a service, dependencies between microservices, or links between a deployment and a system outage. Meanwhile, vector embeddings capture semantic similarities, enabling advanced reasoning across multiple connections.
Another standout feature is temporal awareness. These systems track when data is added, modified, or accessed, ensuring outdated information doesn’t mislead users. For instance, if a team deprecates an API endpoint, active memory recognizes that older documentation referring to that endpoint is no longer valid. It continuously extracts facts from unstructured data, such as updating records when an engineer mentions in Slack, "Alice is now the CTO", by linking "Alice" and "the CTO" automatically.
Advanced retrieval ensures critical information is prioritized. By using a weighted scoring system that balances factors like similarity, recency, and importance, active memory prevents essential details - like known security vulnerabilities - from being overshadowed by less relevant updates.
Benefits of Active Memory
These features provide real, measurable advantages for engineering teams:
- Fresh Context: Active memory keeps up with every change in your codebase and documentation. For example, when a developer updates an API version, the system flags related files needing updates. GitHub applied this in January 2026, resulting in a 7% increase in pull request merge rates (from 83% to 90%).
- Knowledge Consolidation: The system strengthens connections between commonly accessed concepts while letting irrelevant data fade, maintaining a high signal-to-noise ratio. Using structured fact memory (like Mem0) has improved accuracy by 26% and cut latency by 91% compared to traditional context-heavy methods.
- Auditability: Features like "Decision Traces" log who made a decision, when, and why, creating a clear process map. This helps identify gaps or drift in workflows.
| Aspect | Pros | Cons |
|---|---|---|
| Context Quality | Stays current; learns from interactions | Requires ongoing processing resources |
| Reasoning | Handles multi-step entity relationships | More complex to implement compared to RAG |
| Cost | 10x lower for long contexts than RAG | Initial setup needs graph and vector infrastructure |
| Accuracy | 26% boost with structured memory | Needs tenant isolation to avoid memory leakage |
How Active Memory Adapts Over Time
Active memory evolves through reflection loops and intelligent decay. After completing a task, the system reflects on outcomes and stores lessons for future use. For example, a reflection-based memory system called Hindsight improved accuracy from 39% to 83.6%.
It also uses just-in-time verification to ensure accuracy. Memories are stored with references to specific code or documentation, and before acting on them, the system verifies their validity in the current branch. This prevents outdated guidance from influencing decisions.
In January 2026, Ema Agentic OS showcased this adaptability with "Context Graphs" that connected Sales and Support teams. For instance, when a Sales agent approved a 15% discount for a key prospect (Acme) to meet a quarterly deadline, the decision was recorded. Two days later, when Acme filed a support ticket about a shipping delay, the Support agent - powered by the shared Context Graph - immediately recognized Acme’s high value and upgraded them to Platinum Support to align with the original sales intent.
For engineering teams, this means AI agents can work with precise, current insights instead of navigating outdated or conflicting information.
Key Differences Between RAG and Active Memory
Let’s break down the key differences between Retrieval-Augmented Generation (RAG) and active memory, especially when it comes to how they validate information. RAG relies on a static set of documents to verify AI insights, while active memory dynamically updates its knowledge base through ongoing interactions and real-time events. This shift from a fixed retrieval system to one that evolves with new data highlights their contrasting approaches to validation.
The biggest distinction lies in how they handle updates. Active memory is a dynamic, read-write system that continuously extracts, updates, and reconciles facts as they happen. On the other hand, RAG pulls information from a static index that doesn’t change unless it’s manually updated. For instance, if a developer mentions in a team chat that they’ve switched programming languages from Python to TypeScript, active memory will immediately reflect this change. RAG, however, would still reference outdated documentation until someone updates its source.
Another key difference is how they prioritize information. RAG treats all data equally, but active memory uses timestamps and a recency decay formula to rank information. This scoring system - weighted at 0.4 for similarity, 0.35 for recency, and 0.25 for importance - ensures that fresh and relevant context takes precedence. Studies reveal that over 70% of errors in modern language model applications are caused by incomplete or poorly structured context, not by the models themselves. Active memory’s focus on temporal accuracy plays a crucial role in reducing such errors.
Comparison Table: Validation Capabilities
| Dimension | RAG | Active Memory |
|---|---|---|
| Factual Grounding | Static external documents (PDFs, wikis) | Dynamic interactions, tickets, live state |
| Temporal Awareness | None; treats all data as equally current | High; uses timestamps and recency decay |
| Auditability | Tracks provenance to static documents | Tracks fact lineage and state changes |
| Reasoning Capacity | Limited to isolated retrieved chunks | Multi-hop graph traversal across entities |
| Write Path | Read-only; requires manual updating | Read-write; auto-updates facts in real time |
| Search Strategy | Semantic similarity (vector search) | Combines semantic, keyword, graph, and temporal search |
Applications for Engineering Teams
These differences make RAG and active memory suitable for different use cases. RAG works best when dealing with static knowledge. For example, if you’re querying API documentation for a stable library or checking compliance against unchanging regulatory documents, RAG provides reliable, source-based answers. It’s a great fit for HR policies, product documentation, and FAQs - situations where information doesn’t change frequently.
Active memory, on the other hand, excels in dynamic environments. Engineering teams rely on it to monitor live code changes, ticket updates, and developer preferences, ensuring that AI recommendations reflect the latest context. For instance, if a bug gets marked "resolved" yesterday, active memory will immediately note this change. In contrast, RAG would still require manual updates before recognizing the new status.
Increasingly, engineering teams are adopting hybrid systems that combine these two approaches. RAG handles stable organizational knowledge, while active memory manages evolving workflows, creating a balance between consistency and adaptability.
Why Active Memory Works Better for AI Validation
Engineering teams need AI systems that go beyond delivering just accurate and updated information - they need systems that also provide context. This is where active memory excels. Unlike Retrieval-Augmented Generation (RAG), which retrieves documents from a static database, active memory tracks facts along with their reasoning, ensuring insights remain relevant and up-to-date. For example, when an API undergoes a change, active memory prioritizes the new details over outdated ones, making it more effective for engineering workflows.
One of the standout features of active memory is its ability to perform just-in-time verification. It doesn’t just store citations - it cross-checks them with the latest codebase. Imagine a stored memory states, “the authentication service uses OAuth2,” but the current codebase shows a shift to JWT. Active memory flags this discrepancy and updates its records. RAG, on the other hand, lacks this ability to write back or track stale information, making it less dynamic.
"RAG provides knowledge. Agents require wisdom. Knowledge is knowing what the documentation says. Wisdom is remembering that the last three times you followed that documentation, step four didn't work in your production environment."
– Michael Fauscette, CEO & Chief Analyst, Arion Research
Active memory also adapts instantly to changes, like bug fixes or programming language updates. RAG, however, continues to rely on outdated information until its database is manually refreshed.
For engineering teams juggling complex workflows, active memory’s multi-hop reasoning is a game-changer. Instead of pulling isolated snippets of text, it maps relationships across systems. For instance, during a service migration, it can analyze how the change affects specific APIs, identify the responsible teams, and even explain past decisions. This context-aware functionality ensures engineering teams get actionable insights tailored to their environment.
Case Study: Using Knowledge Plane for Active Memory
Knowledge Plane offers a practical example of active memory in action. By combining graph memory and vector memory, it keeps engineering contexts fresh and auditable across entire stacks. Knowledge Plane uses automated tasks, called Skills, to extract, update, and reconcile facts as events occur. For instance, if a developer updates a service dependency, mentions a preference in Slack, or closes a Jira ticket, Knowledge Plane updates its shared memory in real-time.
The system’s graph-based design enables it to understand connections that flat vector searches miss. By integrating tools like code repositories, Slack, and service catalogs, it can, for example, determine the ideal reviewer for an API change based on timestamped, verifiable sources.
Auditability is another key strength. Every piece of data stored in Knowledge Plane includes a citation, whether it’s from a specific line of code, a Slack message, or a ticket comment. This transparency ensures that when an AI agent makes a suggestion, users can see exactly where the information came from and when it was last verified.
GitHub showcased similar functionality in January 2026 with its cross-agent memory system for Copilot, spearheaded by Principal ML Engineer Tiferet Gazit. In one scenario, a Code Review agent identified a pattern for API synchronization in a pull request and stored it with citations. When a Coding agent later updated the API, it verified the stored information and applied the synchronization across the SDK, server routes, and documentation. This approach boosted pull request merge rates from 83% to 90% and significantly improved code quality (p-value <0.00001).
Engineering Use Cases for Active Memory
Active memory’s strengths extend across various engineering scenarios. For example, during a service migration, it can immediately pinpoint which APIs are affected, notify the relevant teams, and identify documentation needing updates - all by leveraging its relationship graph. In contrast, RAG would require manual updates across multiple documents to achieve the same outcome.
Another advantage is its ability to track developer habits and patterns. If a developer consistently uses a particular testing framework or follows specific review practices, active memory captures these preferences. This allows AI agents to provide tailored recommendations that go beyond static documentation.
In January 2026, Ema's Agentic Employee for Sales demonstrated how active memory can benefit customer support. A Sales agent approved a 15% discount for a high-value prospect named "Acme" to close a last-minute deal. This decision, along with its reasoning, was recorded in a Context Graph. Later, when a Support agent handled a shipping delay for Acme, the system recognized the company’s high value and upgraded them to "Platinum Support" without requiring a manual query - preserving the original sales intent.
Active memory also shines in code review automation. For instance, it can identify recurring issues across pull requests and store solutions with citations. If synchronizing API version numbers across multiple files has been a problem in the past, active memory ensures future agents automatically apply the correct pattern during updates, preventing integration errors before they occur.
Choosing Between RAG and Active Memory
Selecting the right validation system boils down to your team's specific needs. The decision typically hinges on three main factors: how often your data changes, the level of context your AI needs to maintain, and whether you're dealing with one-time questions or aiming to build a long-term understanding.
When to Use RAG
RAG (Retrieval-Augmented Generation) shines when you need quick, factual answers from a stable and extensive document base. Think of situations where users frequently access technical manuals, HR policies, or product documentation that doesn't change often. In these cases, RAG acts as a fast and efficient search tool. It's particularly useful for tasks like creating documentation assistants or powering enterprise search tools.
When to Use Active Memory
Active memory is the way to go when your team handles relational data that evolves over time and demands traceability. If your AI must learn from past interactions, monitor ongoing project changes, or understand the interplay between different parts of your system, active memory is the better fit. Teams working with shifting codebases, architectural decisions, or dependencies across departments will find this approach invaluable.
Interestingly, research indicates that over 70% of errors in modern LLM applications stem from incomplete or poorly structured context. By implementing structured active memory, accuracy can improve by 35–60% in enterprise environments.
Implementation Considerations
For many teams, combining RAG and active memory delivers the best results. However, implementing active memory requires more infrastructure than RAG alone. For example, you'll need tenant isolation to prevent cross-user access to stored preferences. Additionally, a robust write path is essential for extracting facts, resolving entities, and reconciling conflicting updates.
A hybrid approach often works best in production settings. Use RAG for universal knowledge, like technical documentation, and active memory for user-specific context and organizational history. This method allows you to maintain a thorough reference library while also building a dynamic, institutional memory.
Knowledge Plane exemplifies this hybrid strategy by integrating graph and vector memory systems. Its Skills feature automates the extraction and updating of facts from sources like code repositories, Slack conversations, and ticketing systems. This setup ensures AI agents first query internal memory - asking, "Do I already know this?" - before resorting to RAG for external data. This process not only reduces latency but also cuts down API costs.
That said, adding a memory layer can increase retrieval latency by 50–200 milliseconds. To ensure high-quality context, keep an eye on critical metrics: aim for an Answer Faithfulness rate above 90% and a Hallucination Rate below 5%.
Conclusion
When deciding between RAG and active memory, it’s essential to recognize the unique strengths of each. RAG excels at delivering quick answers from static sources like technical manuals or product specifications. On the other hand, active memory functions more like a dynamic brain, learning from past interactions, adapting to changes over time, and understanding how different components of a system relate to one another.
The primary distinction lies in how they handle information: RAG is read-only, retrieving data without modifying it, while active memory continuously updates and refines its knowledge as projects progress. This difference is especially important for engineering teams managing evolving codebases, shifting architectural decisions, and dependencies across teams.
"RAG is a powerful tool for reading the library. Agentic Memory is the ability to write the autobiography." – Michael Fauscette, Founder and CEO, Arion Research
For teams navigating complex and ever-changing data, active memory systems like Knowledge Plane provide a practical solution. These systems ensure AI agents first consult their internal memory - asking, “Do I already know this?” - before resorting to external RAG lookups. This method keeps context up-to-date, improves traceability, and reduces repeated errors by maintaining a reliable, verified understanding of recent developments.
FAQs
How do I know if my data is 'static' enough for RAG?
Your data is suitable for RAG (Retrieval-Augmented Generation) if it doesn't change often. Since RAG depends on a fixed external knowledge base, it works best with information that remains relatively stable over time. However, if your data updates frequently, RAG might generate outdated or irrelevant responses. For scenarios involving constantly changing data, it's better to explore systems that can handle frequent updates while keeping the context current.
What does 'just-in-time verification' mean in active memory?
Just-in-time verification in active memory refers to the ongoing process of checking and updating an AI system's memory as interactions occur. This approach ensures the information remains accurate and up-to-date, enabling the system to preserve context and analyze relationships effectively in real time.
Can I combine RAG and active memory in one system?
Yes, it’s possible to integrate Retrieval-Augmented Generation (RAG) with active memory systems within a single AI framework. RAG excels at delivering responses based on static, factual knowledge, while active memory focuses on tracking and adapting to evolving context and relationships over time. By combining these approaches, you can build a hybrid system that merges RAG’s strength in accuracy with active memory’s ability to handle continuity, personalization, and dynamic state management.